

The Prompt Caching in OpenAI API feature is a powerful optimization that helps developers cut costs and improve application performance when working with large prompts. Whether you are building chatbots, retrieval-augmented generation (RAG) pipelines, or multi-step AI workflows, prompt caching can make your application faster and cheaper without requiring extra code changes.
What Is Prompt Caching?
Prompt caching allows the API to reuse previously processed tokens from the prefix of your input. Instead of reprocessing the same instructions, schemas, or long system prompts every time, the API discounts them if they have been seen recently.
- Eligible after 1,024 input tokens
- Works in 128-token increments
- Applies to the longest common prefix across your requests
This means you pay less for tokens that are identical and reused at the start of your prompts.
How It Helps Reduce OpenAI API Cost
By default, every input token is billed at the standard rate. With caching:
- Uncached input tokens: billed at the full price
- Cached input tokens: billed at ~50% discount
- Output tokens: unchanged, full price
For example, with GPT-4o:
- Standard input: $2.50 / 1M tokens
- Cached input: $1.25 / 1M tokens
If your application sends long system instructions or tool schemas repeatedly, caching significantly reduces OpenAI API cost.
How Prompt Caching Improves API Latency
Caching not only lowers cost—it also reduces request latency. Since the API doesn’t need to reprocess cached tokens, responses are faster.
This is especially valuable in production applications like:
- Real-time chat assistants
- Customer support bots
- Agent frameworks where tools are repeatedly invoked
By reusing cached prefixes, developers can both optimize token usage and improve overall API responsiveness.
How Long Does the Cache Last?
- Caches typically last 5–10 minutes of inactivity
- Always cleared within 1 hour
- Caches are not shared between organizations
This is short-lived, so caching is best for active sessions with multiple back-and-forth requests.
How to Track Cached Tokens
When you send a request, the API response includes usage details. Look for:
"usage": {
"prompt_tokens_details": {
"cached_tokens": 1024
}
}
If cached_tokens > 0, those were billed at the discounted rate. Monitoring this helps you evaluate caching efficiency and measure savings.
Python Example: Checking Cached Tokens
Here’s the Python snippet that shows how to check cached tokens in a response:
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain how prompt caching works in simple terms."}
]
)
# Print the response text
print(response.output[0].content[0].text)
# Check how many tokens were cached
cached_tokens = response.usage.prompt_tokens_details.cached_tokens
print(f"Cached tokens in this request: {cached_tokens}")
This will output both the model’s answer and the number of cached tokens billed at the discounted rate.
Real Example: Customer Support Chatbot
Let’s say you are building a customer support chatbot for an e-commerce site.
- Your system message is 1,500 tokens long. It includes rules, product FAQs, escalation steps, and tone guidelines.
- Each customer message is only 50–100 tokens.
Without prompt caching:
- Every request reprocesses the 1,500-token system message.
- If you handle 10,000 chats per day, that’s 15 million system tokens billed at the full rate.
With prompt caching:
- The 1,500-token system message is cached after the first call.
- Each follow-up message only reuses that cached prefix.
- Instead of 15 million tokens billed at full price, most of them are billed at half price.
Result: You save thousands of dollars per month and the chatbot feels faster for customers because cached tokens reduce latency.
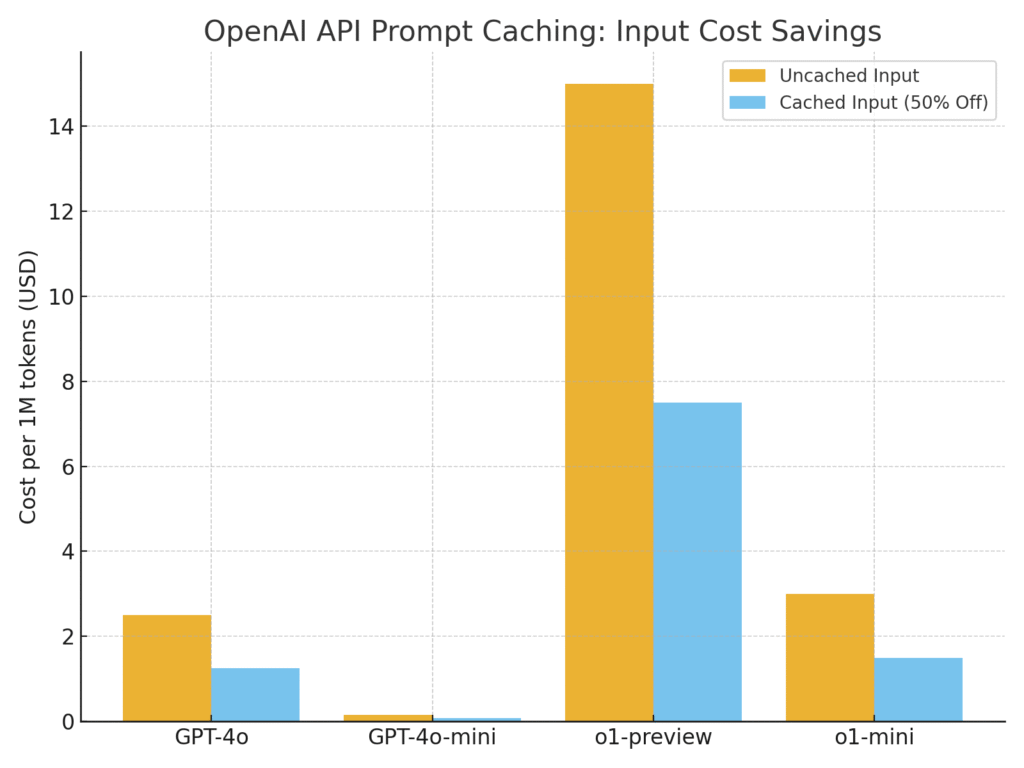
Cost Breakdown: Before vs After Prompt Caching
The table below shows how input token pricing changes when Prompt Caching in OpenAI API is applied. Cached tokens are billed at ~50% discount, while output tokens remain the same.
| Model | Uncached Input | Cached Input | Output | Savings per 1M Cached Tokens |
|---|---|---|---|---|
| GPT-4o (2024-08-06) | $2.50 / 1M tokens | $1.25 / 1M tokens | $10.00 / 1M | $1.25 |
| GPT-4o-mini (2024-07-18) | $0.15 / 1M tokens | $0.075 / 1M tokens | $0.60 / 1M | $0.075 |
| o1-preview | $15.00 / 1M tokens | $7.50 / 1M tokens | $60.00 / 1M | $7.50 |
| o1-mini | $3.00 / 1M tokens | $1.50 / 1M tokens | $12.00 / 1M | $1.50 |
| Fine-tuned models | Same 50% discount applies |
Cost Calculation Example
Let’s do the math for a simple scenario.
- System instruction (prefix): 1,500 tokens
- User query (new content each time): 100 tokens
- Total tokens per request: 1,600
- Number of requests per day: 100,000
- Model used: GPT-4o (input cost = $2.50 per 1M tokens)
Without Prompt Caching
- Input tokens per request: 1,600
- Total input tokens for 100k requests: 160,000,000 (160M)
- Cost = (160,000,000 ÷ 1,000,000) × 2.50 = $400
With Prompt Caching
- First request: full 1,600 tokens billed at normal rate
- Remaining 99,999 requests:
- 1,500 cached tokens (50% off = $1.25 per 1M)
- 100 uncached tokens (normal $2.50 per 1M)
Cost for cached tokens = (1,500 × 99,999 ÷ 1,000,000) × 1.25 ≈ $187.50
Cost for uncached tokens = (100 × 99,999 ÷ 1,000,000) × 2.50 ≈ $25.00
Total with caching ≈ $212.50
Savings
- Without caching: $400
- With caching: $212.50
- Money saved: $187.50 (≈47% less)
At larger scale, these savings multiply quickly, which is why prompt caching is so important for high-traffic applications.
Best Practices to Maximize Prompt Caching
To get the most from prompt caching in OpenAI API, follow these guidelines:
- Keep stable content at the top
- System message, policies, and tool schemas should always come first.
- This ensures they form the shared prefix.
- Put dynamic content at the bottom
- User input, retrieved documents, or fresh context should go later in the prompt.
- This prevents cache invalidation.
- Use embeddings for semantic variation
- If user queries are similar but not identical, embedding-based caching can complement prompt caching for even greater efficiency.
- Monitor with logs
- Track
cached_tokensin responses to continuously optimize token usage.
- Track
Why It Matters for Developers
If you are scaling an AI product, cost and speed are critical. Prompt caching directly addresses both:
- Cost savings → lower input token spend
- Performance boost → faster response times
- Developer simplicity → no code changes required
For applications that reuse structured instructions or chain prompts, prompt caching is a must-have optimization.
Frequently Asked Questions (FAQ)
1. How does prompt caching work and what are its cost implications?
Prompt caching works by reusing the starting portion (prefix) of your prompt if it has been processed recently. Once a prefix is cached, the API charges ~50% less for those tokens in later requests. Only input tokens benefit from caching; output tokens remain billed at the normal rate. At scale, this can save tens of thousands of dollars per month for applications with long, repeated system prompts or tool schemas.
2. What’s the difference between the Responses API and Prompt Caching?
The Responses API is the endpoint you use to interact with models like GPT-4o. It provides structured output, streaming, tool calls, and usage reporting.
Prompt caching is an internal optimization of the API: when you send long prompts repeatedly, cached prefixes are discounted. In short:
- Responses API = how you send and receive AI responses.
- Prompt caching = how the API reduces cost and latency behind the scenes when prefixes repeat.
3. How can I use the cached_tokens field to calculate cost estimation?
The API returns usage details in each response. Example:
"usage": {
"prompt_tokens": 1600,
"prompt_tokens_details": {
"cached_tokens": 1500
}
}
- Here, 1,500 tokens were billed at the cached (discounted) rate.
- The remaining 100 tokens were billed at full price.
You can calculate cost by applying the model’s cached input rate tocached_tokensand the uncached rate to the rest. This helps you measure how much you’re saving in real time.
4. Is Prompt Caching available for o3-mini?
No. As of now, prompt caching is not supported for o3-mini models. It is available for GPT-4o, GPT-4o-mini, o1-preview, o1-mini, and fine-tuned models.
5. Are output tokens discounted with prompt caching?
No. Prompt caching only applies to input tokens that are part of a cached prefix. Output tokens are always billed at the full rate.
6. How can I check if caching is being used in my requests?
Check the cached_tokens field inside the usage.prompt_tokens_details object in the API response. If the value is greater than zero, caching was applied and those tokens were billed at the discounted rate. If it’s zero, no cached tokens were used.
Conclusion
Prompt Caching in OpenAI API is a game-changer for teams building with LLMs. By reusing stable prefixes across calls, you can reduce OpenAI API cost, optimize token usage, and improve API latency—all without extra engineering work.
As your prompts get longer and more complex, caching ensures efficiency, scalability, and better user experience.
Comments