

Imagine asking an AI a complex question and instead of immediately blurting out an answer, it pauses… thinks… evaluates different approaches… and then responds with a carefully reasoned solution. That’s not science fiction—that’s Gemini 3, and it’s rewriting the rules of what developers can build with AI.
What Makes Gemini 3 Different? (The “Aha!” Moment)
Let’s start with a story. Remember the last time you faced a really tough coding problem? You didn’t just start typing immediately, right? You probably grabbed coffee, sketched some diagrams, considered different approaches, maybe even slept on it. That’s essentially what Gemini 3 does—and it’s a fundamental shift from how AI models traditionally work.
The Extended Thinking Revolution
Previous AI models were like that classmate who always raised their hand first—fast, but not always right. They generated responses in one shot, token by token, with no opportunity to reconsider or refine their approach.
Gemini 3 changes everything. It can enter “extended thinking mode” where it:
- Explores multiple solution pathways
- Evaluates trade-offs between approaches
- Reconsiders initial assumptions
- Validates reasoning before responding
Think of it as the difference between a snap quiz answer and a take-home exam where you can research, draft, and refine your work.
The Gemini 3 Family Tree
Before diving deeper, let’s clarify what we’re talking about:
Gemini 3 Pro – The production-ready powerhouse. This is what you’ll use in real applications.
Gemini 3 Deep Think – The experimental variant that pushes extended thinking to the extreme. It takes even more time to reason but achieves breakthrough performance on ultra-hard problems.
Gemini 3 Pro Experimental – Early access to cutting-edge features before they hit general availability. Perfect for developers who like living on the edge.
Reading the Tea Leaves: Understanding Gemini 3 Benchmarks
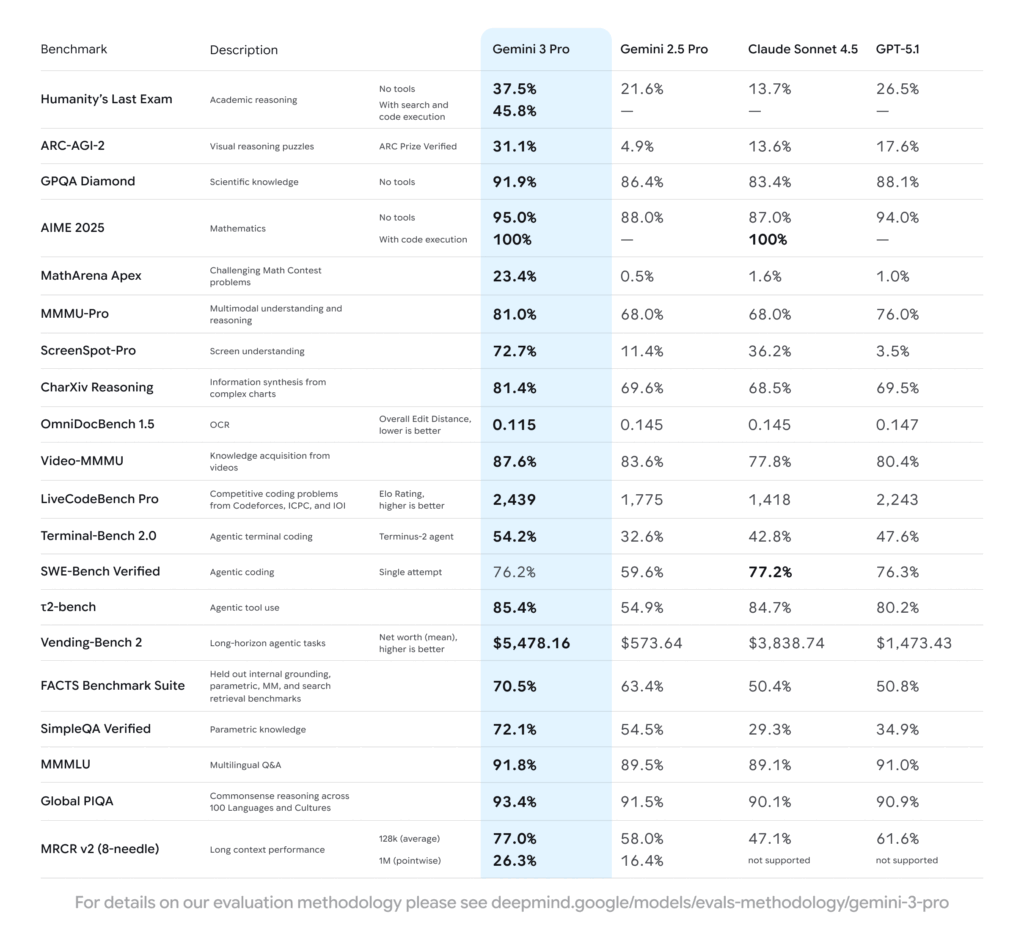
Now, let’s talk about those impressive numbers you’ve probably seen. But here’s the thing—benchmarks aren’t just bragging rights. They’re a crystal ball showing you what your AI-powered application can actually do.
The “Holy Grail” Benchmarks (What They Really Mean)
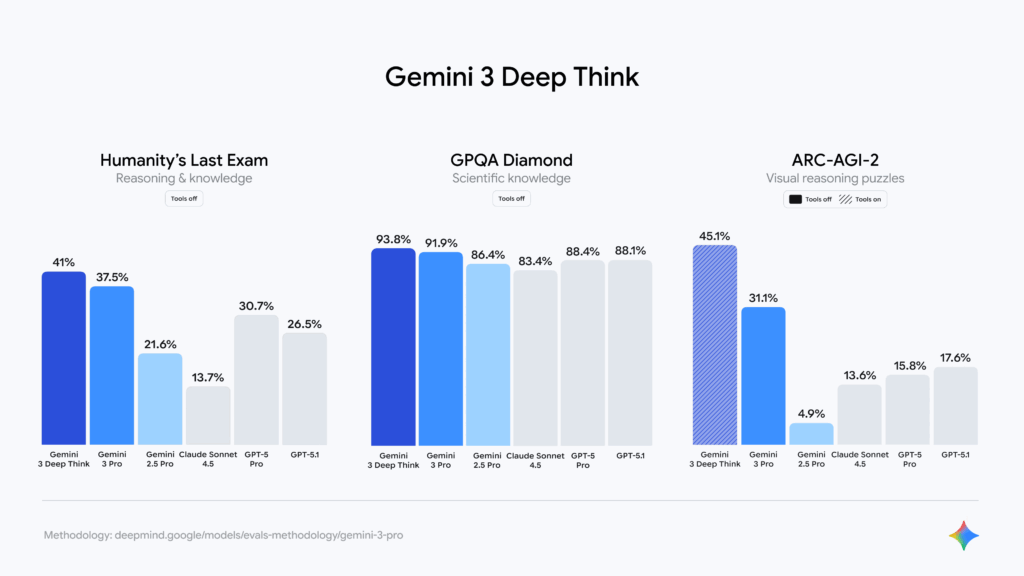
Humanity’s Last Exam (37.5% → 45.8% with tools)
What it tests: The kind of questions that make PhD students sweat—advanced reasoning across science, math, and humanities.
What it means for you: If you’re building educational platforms, research assistants, or anything requiring deep analytical thinking, Gemini 3 use becomes a game-changer. The jump from 37.5% to 45.8% when tools are enabled? That’s the secret sauce—Gemini 3 doesn’t just know things, it knows when to search, calculate, or execute code to verify its reasoning.
Real-world application: Imagine building a tutoring app where students ask “Why does quantum entanglement seem to violate Einstein’s relativity?” Gemini 3 can break down the misconception, search for recent research if needed, and provide a nuanced explanation that actually teaches.
GPQA Diamond (91.9%)
What it tests: Graduate-level scientific questions that require deep domain expertise.
What it means for you: Building medical diagnostic assistants, scientific research tools, or technical documentation systems? This 91.9% score means Gemini 3 Pro can handle specialist knowledge reliably. Compare that to GPT-5.1’s 88.1%—that 3.8% difference translates to dozens of correct answers over incorrect ones in a production system.
Real-world application: A biotech startup could build a research assistant that helps scientists explore literature, suggest experimental approaches, and identify potential drug interactions with Ph.D.-level understanding.
ARC-AGI-2 (45.1% with tools)
What it tests: Visual reasoning puzzles that even humans find challenging. These aren’t “is this a cat or dog” questions—they’re pattern recognition and spatial reasoning tasks.
What it means for you: This is huge for computer vision applications. The 45.1% with tools (compared to competitors struggling to break 20%) means Gemini 3 use in visual AI is exceptionally strong.
Real-world application: Build automated UI testing tools that understand what elements should do based on visual context, not just coded selectors. Or create accessibility tools that can describe complex diagrams to visually impaired users with genuine understanding.
The Coding Benchmarks (Where Rubber Meets Road)
Let’s talk about what really matters to developers—can this thing code?
LiveCodeBench Pro (Elo: 2,439)
For non-chess players, think of Elo ratings like developer skill levels. An Elo of 2,439 puts Gemini 3 Pro in “senior developer” territory. It’s not just generating boilerplate—it’s solving competitive programming challenges from platforms like Codeforces.
What this means practically:
- Junior developers get an AI pair programmer that can actually explain why an algorithm works
- Senior developers get a capable assistant for exploring edge cases and alternative implementations
- Teams can automate complex refactoring tasks with confidence
SWE-Bench Verified (76.2%)
This benchmark is brutal—it pulls real GitHub issues from popular open-source projects and asks the AI to fix them. We’re talking about real bugs in real codebases with all their messy complexity.
At 76.2%, Gemini 3 Pro can successfully resolve three out of every four real-world software engineering issues. That’s not a coding assistant—that’s a teammate.
Practical example: Feed Gemini 3 your GitHub repository, point it at an open issue, and watch it:
- Analyze the codebase structure
- Identify the root cause
- Propose a fix that follows your project’s conventions
- Even suggest test cases
Terminal-Bench 2.0 (54.2%)
This tests “agentic coding”—the ability to work autonomously in a development environment. Installing packages, running tests, debugging errors, iterating on solutions.
The 54.2% score means Gemini 3 can successfully complete over half of complex, multi-step development tasks autonomously. Imagine telling your AI: “Add OAuth authentication to the API” and coming back to find it done—dependencies installed, code implemented, tests passing.
The Multimodal Magic (Beyond Just Text)
ScreenSpot-Pro (72.7%)
This benchmark tests whether AI can understand and interact with user interfaces—clicking the right buttons, filling forms, navigating apps.
Revolutionary use case: Build accessibility tools that can navigate websites for users who can’t use a mouse. Create automated testing that understands UI intent, not just brittle CSS selectors. Develop customer support bots that can actually show customers where to click.
Video-MMMU (87.6%)
At 87.6%, Gemini 3 doesn’t just “see” video frames—it understands temporal relationships, follows narratives, and extracts knowledge from visual sequences.
Killer applications:
- Automatic video summarization for educational content
- Sports analytics that understand game strategy from footage
- Security systems that recognize suspicious behavioral patterns
- Content moderation that catches context-dependent violations
From Zero to Hero: Practical Gemini 3 Use Cases
Let’s get concrete. Here are real scenarios showing how developers at different skill levels can leverage Gemini 3.
For Fresh Graduates & Junior Developers
Use Case 1: Your Personal Code Mentor
// Instead of Googling "how to implement rate limiting"
// You can have a conversation with Gemini 3
Prompt: "I need to add rate limiting to my Express.js API.
Explain the concepts, show me implementation options,
and help me choose the right approach for a small SaaS app."
Gemini 3 will:
- Explain rate limiting concepts (token bucket vs sliding window)
- Show code implementations for each approach
- Discuss trade-offs (memory usage, precision, edge cases)
- Recommend based on your specific context
- Point you to relevant libraries and best practices
Why this works: The 91.9% GPQA Diamond score means it can explain complex technical concepts accurately. The coding benchmarks mean the code it generates actually works.
Use Case 2: Debug Detective
Stuck on a bug? Instead of spending hours adding console.logs everywhere:
# Share your buggy code with Gemini 3
Prompt: "This function should sort users by signup date,
but users registered on the same day appear in random order.
Here's my code: [paste code]
What's wrong and how do I fix it?"
Gemini 3’s extended thinking mode means it won’t just guess—it’ll trace through the logic, identify the edge case you missed (probably a missing secondary sort key), and explain the fix with examples.
For Mid-Level Developers
Use Case 3: Architecture Advisor
Prompt: "I'm building a real-time collaborative editing feature
like Google Docs. Compare CRDT vs Operational Transform approaches.
Consider: 5-10 concurrent users, React frontend,
Node.js backend, budget for AWS services."
Here’s where Gemini 3 Pro shines. That 45.8% Humanity’s Last Exam score with tools means it can:
- Research current best practices (using web search tools)
- Analyze trade-offs specific to your constraints
- Provide code examples for both approaches
- Estimate implementation complexity and AWS costs
- Reference real-world implementations for learning
Use Case 4: Code Review Partner
Share your PR with Gemini 3 before your team reviews it:
Prompt: "Review this pull request for:
- Security vulnerabilities
- Performance bottlenecks
- Edge cases I might have missed
- Consistency with REST best practices
[paste PR diff]"
The SWE-Bench Verified score of 76.2% means it understands real codebase complexity and can spot issues a senior developer would catch.
For Senior Developers & Architects
Use Case 5: System Design Collaborator
Prompt: "Design a distributed job queue system handling
100K jobs/minute with these requirements:
- At-least-once delivery guarantee
- Priority scheduling
- Failed job retry with exponential backoff
- Monitoring and observability
Propose an architecture using AWS services,
explain trade-offs, and identify potential bottlenecks."
Gemini 3’s extended thinking mode excels here. It’ll evaluate multiple architectural patterns (SQS vs Kinesis vs Kafka, Lambda vs ECS vs EC2), consider failure modes, and provide a thoughtful design document-level response.
Use Case 6: Legacy Code Modernization
Prompt: "Analyze this 5000-line legacy PHP codebase.
Identify:
1. Core business logic that needs preservation
2. Security vulnerabilities
3. Migration path to modern PHP 8.3 or Node.js
4. Which parts can be automated vs need manual rewrite
[attach codebase]"
The long-context capability (77% on 128K token context) means Gemini 3 can actually comprehend your entire codebase, not just snippets.
Use Case 7: Automated Agentic Development
This is cutting-edge. Using the Terminal-Bench capabilities:
# Pseudocode for an autonomous development agent
task = "Add GraphQL API alongside existing REST API"
agent = GeminiAgent(mode="deep_think")
result = agent.execute(
task=task,
codebase_path="./my-project",
permissions=["install_packages", "run_tests", "create_files"]
)
# Agent autonomously:
# 1. Analyzes existing REST implementation
# 2. Installs Apollo Server
# 3. Generates GraphQL schemas from REST models
# 4. Creates resolvers
# 5. Writes integration tests
# 6. Runs tests and fixes failures
# 7. Generates documentation
The 54.2% Terminal-Bench score means this isn’t fantasy—it works over half the time for complex tasks. With human oversight, it becomes a productivity multiplier.
The Technical Deep Dive: How to Actually Use Gemini 3
Understanding Thinking Modes
Gemini 3 offers different “thinking depths”—and choosing correctly impacts both results and costs.
Standard Mode (Default)
- Response time: 1-3 seconds
- Best for: Quick queries, simple code generation, straightforward questions
- Think of it as: Your first-draft generator
Extended Thinking Mode (High)
- Response time: 5-15 seconds
- Best for: Complex reasoning, multi-step problems, critical decisions
- Think of it as: Your peer review process
Deep Think Mode (Experimental)
- Response time: 30+ seconds
- Best for: Research-level problems, novel algorithm design, complex system architecture
- Think of it as: Your senior architect’s design review
Choosing the right mode:
# Simple query - Standard mode
response = model.generate_content(
"Write a function to validate email addresses"
)
# Complex reasoning - Extended thinking
response = model.generate_content(
"Design a rate limiting algorithm that prevents abuse "
"while allowing burst traffic from legitimate users",
thinking_mode="high"
)
# Research-level - Deep think
response = model.generate_content(
"Propose a novel approach to distributed consensus "
"that reduces network overhead compared to Raft",
thinking_mode="deep"
)
Tool Use: The Secret Weapon
Remember how Gemini 3’s score jumped from 37.5% to 45.8% on Humanity’s Last Exam with tools enabled? That’s because tool use transforms Gemini 3 from knowledgeable to capable.
What tools can Gemini 3 use?
- Web Search: Finding current information beyond training data
- Code Execution: Running Python to verify calculations or test logic
- Custom Functions: Your own APIs and services
Example: Building a Smart Financial Advisor
# Define tools Gemini 3 can use
tools = [
{
"name": "get_stock_price",
"description": "Get current stock price for a ticker symbol",
"parameters": {"ticker": "string"}
},
{
"name": "calculate_portfolio_risk",
"description": "Calculate risk metrics for a portfolio",
"parameters": {"holdings": "array"}
},
{
"name": "search_financial_news",
"description": "Search recent financial news",
"parameters": {"query": "string", "days": "number"}
}
]
# Gemini 3 decides which tools to use and when
response = model.generate_content(
"Should I invest in NVIDIA stock given current market conditions? "
"I have a moderate risk tolerance and 10-year horizon.",
tools=tools
)
# Behind the scenes, Gemini 3 might:
# 1. Call get_stock_price("NVDA")
# 2. Call search_financial_news("NVIDIA semiconductor")
# 3. Reason about risk vs reward
# 4. Provide personalized recommendation
The 85.4% t2-bench score means Gemini 3 reliably chooses the right tools at the right time—it’s not just throwing random API calls at problems.
Multimodal Development Patterns
Pattern 1: Visual Code Understanding
# Upload a screenshot of a UI bug
with open("bug_screenshot.png", "rb") as img:
image_data = img.read()
response = model.generate_content([
"This button should be blue but appears gray. ",
"Here's a screenshot. Identify the CSS issue.",
{"mime_type": "image/png", "data": image_data}
])
# Gemini 3 can visually see the gray button,
# infer CSS properties, and suggest fixes
Pattern 2: Video Analysis for Development
# Analyze a screen recording of user interaction
response = model.generate_content([
"User is struggling to complete checkout. ",
"Watch this session recording and identify UX issues.",
{"mime_type": "video/mp4", "data": video_data}
])
# The 87.6% Video-MMMU score means it can spot:
# - Confusing button placement
# - Unclear error messages
# - Performance stutters causing frustration
Managing Long Context (The 128K Superpower)
Most developers don’t realize they can feed Gemini 3 their entire codebase. The 77% MRCR benchmark score at 128K tokens means it maintains comprehension over roughly 100,000 words.
Practical example:
# Load entire project
codebase = ""
for file in glob.glob("src/**/*.js", recursive=True):
with open(file) as f:
codebase += f"\n\n// File: {file}\n{f.read()}"
# Ask comprehensive questions
response = model.generate_content(
f"Here's my entire codebase:\n\n{codebase}\n\n"
"Identify: 1) Circular dependencies 2) Unused exports "
"3) Inconsistent error handling patterns"
)
This is impossible with traditional tools—you’re getting AI-powered codebase intelligence at project scale.
Advanced Techniques: From Good to Great
Prompt Engineering for Gemini 3
Gemini 3’s extended thinking means you can be more conversational and less prescriptive. Traditional prompting wisdom was “be extremely specific.” With Gemini 3, you can treat it more like a colleague.
Old-school prompt (still works):
Task: Implement binary search
Language: Python
Requirements:
- Handle empty array
- Return -1 if not found
- Include docstring
- Add type hints
- Write 3 test cases
Gemini 3-optimized prompt (often better):
I need a robust binary search implementation.
Show me how you'd write this considering edge cases,
and explain trade-offs in your design choices.
The second prompt leverages extended thinking—Gemini 3 will consider various approaches before responding, often producing more thoughtful results.
Chain-of-Thought Amplification
Explicitly ask Gemini 3 to show its reasoning:
Prompt: "Before implementing, think through:
1. What could go wrong?
2. What assumptions am I making?
3. How would I test this?
Then implement a rate limiter for our API."
This works exceptionally well because it aligns with how Gemini 3’s extended thinking operates internally.
Iterative Refinement Pattern
# First pass - exploration
response1 = model.generate_content(
"Propose 3 different approaches to implement "
"real-time notifications in our app"
)
# Second pass - deep dive
response2 = model.generate_content(
f"You suggested: {response1.text}\n\n"
"Let's go with WebSockets. Now design the complete "
"architecture considering: scaling to 10K concurrent "
"connections, authentication, fallback strategies."
)
# Third pass - implementation
response3 = model.generate_content(
f"Based on this architecture: {response2.text}\n\n"
"Implement the server-side WebSocket handler with "
"connection management and authentication."
)
Each iteration builds on previous reasoning—leveraging Gemini 3’s comprehension and consistency.
Real-World Integration: Building Production Systems
Architecture Pattern: AI-Powered Development Pipeline
Here’s how a modern development team might integrate Gemini 3:
┌─────────────┐
│ Developer │
│ Opens PR │
└──────┬──────┘
│
▼
┌─────────────────────────────────────┐
│ Gemini 3 Automated Review Agent │
│ -------------------------------- │
│ 1. Security scan │
│ 2. Performance analysis │
│ 3. Test coverage check │
│ 4. Architecture consistency │
│ 5. Documentation completeness │
└──────┬──────────────────────────────┘
│
▼
┌─────────────────┐
│ Review Summary │
│ Posted to PR │
└─────────────────┘
Implementation sketch:
// GitHub webhook handler
app.post('/webhook/pr', async (req, res) => {
const { pull_request } = req.body;
// Fetch PR diff
const diff = await github.pulls.get({
owner, repo,
pull_number: pull_request.number
});
// Gemini 3 analysis with extended thinking
const review = await model.generateContent({
contents: [{
role: "user",
parts: [{
text: `Review this PR for production readiness:\n${diff.data.patch}`
}]
}],
generationConfig: {
thinking_mode: "high" // Extended thinking for thorough review
}
});
// Post review as comment
await github.issues.createComment({
owner, repo,
issue_number: pull_request.number,
body: review.response.text()
});
});
Cost Optimization Strategies
Let’s be real—AI API calls cost money. Here’s how to optimize Gemini 3 use economically:
Strategy 1: Tiered Thinking
# Quick filter with standard mode (cheap)
quick_check = model.generate_content(
f"Is this code snippet likely to have security issues? "
f"Yes/No only:\n{code}"
)
# Deep analysis only if needed (expensive)
if "Yes" in quick_check.text:
detailed_analysis = model.generate_content(
f"Identify and explain security vulnerabilities:\n{code}",
thinking_mode="high"
)
Strategy 2: Caching Common Patterns
# Cache common queries
cache = {}
def cached_generate(prompt, **kwargs):
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
response = model.generate_content(prompt, **kwargs)
cache[cache_key] = response
return response
# Saves money on repeated queries like:
# - "Explain REST vs GraphQL"
# - "How does OAuth work?"
# - Common code patterns
Strategy 3: Batch Processing
# Instead of 10 separate API calls
for bug in bug_reports:
analysis = model.generate_content(f"Analyze: {bug}")
# Batch into one call
combined_prompt = "\n\n---\n\n".join([
f"Bug {i}: {bug}" for i, bug in enumerate(bug_reports)
])
analysis = model.generate_content(
f"Analyze each bug report separately:\n\n{combined_prompt}"
)
Common Pitfalls & How to Avoid Them
Pitfall 1: Overusing Extended Thinking
Mistake:
# Using extended thinking for simple queries
response = model.generate_content(
"What's 2 + 2?",
thinking_mode="deep" # Overkill
)
Fix:
# Match complexity to thinking mode
response = model.generate_content("What's 2 + 2?") # Standard mode
response = model.generate_content(
"Design a distributed consensus algorithm",
thinking_mode="deep" # Justified
)
Pitfall 2: Not Leveraging Tools
Mistake:
# Asking about current stock prices without tools
response = model.generate_content(
"What's NVIDIA's current stock price?"
)
# Gets: "I don't have real-time data..."
Fix:
# Enable web search tool
response = model.generate_content(
"What's NVIDIA's current stock price?",
tools=[{"web_search": {}}]
)
# Gets: Actual current price
Pitfall 3: Ignoring Context Limits
Mistake:
# Dumping massive codebase without structure
giant_blob = read_entire_monorepo() # 500K tokens
response = model.generate_content(f"Fix bugs in: {giant_blob}")
# Fails or loses details
Fix:
# Hierarchical analysis
# First pass: identify problem areas
structure = get_codebase_structure()
hotspots = model.generate_content(
f"Which modules likely contain bugs based on structure:\n{structure}"
)
# Second pass: deep dive on specific modules
for module in identified_modules:
analysis = model.generate_content(
f"Detailed bug analysis:\n{read_module(module)}"
)
Pitfall 4: Treating AI Output as Infallible
Mistake:
code = model.generate_content("Write a payment processing function").text
exec(code) # NEVER DO THIS
deploy_to_production()
Fix:
code = model.generate_content("Write a payment processing function").text
# Always review generated code
print("Review this code:")
print(code)
# Run tests
test_results = run_test_suite(code)
# Manual verification
if test_results.passed and human_approved:
deploy_to_production()
Even at 76.2% SWE-Bench success rate, that’s still 23.8% that needs human oversight.
Measuring Success: Beyond Benchmarks
Benchmarks tell you what Gemini 3 can do. Here’s how to measure what it actually does for your team:
Metrics That Matter
For Junior Developers:
- Time to resolution for common problems (should decrease 40-60%)
- Code review iterations per PR (should decrease as code quality improves)
- Learning velocity (concepts mastered per month)
For Senior Developers:
- Architecture decision documentation time (should decrease 50%+)
- Code review thoroughness (should increase with AI-assisted reviews)
- Experimentation speed (prototype to proof-of-concept time)
For Teams:
- Bug escape rate (bugs reaching production)
- Technical debt reduction rate
- Documentation completeness score
A/B Testing Your AI Integration
# Experiment framework
class DevelopmentMetrics:
def __init__(self, dev_id, uses_gemini):
self.dev_id = dev_id
self.uses_gemini = uses_gemini
def track_pr(self, pr_data):
metrics = {
'time_to_first_commit': pr_data.first_commit_time,
'review_cycles': pr_data.review_count,
'bugs_found_in_qa': pr_data.qa_bugs,
'test_coverage': pr_data.coverage_pct
}
# Store and analyze trends
Run this for 3 months, compare Gemini 3 users vs non-users, make data-driven decisions.
The Future: Where Gemini 3 Use Is Heading
Emerging Patterns
Autonomous Development Agents
Current state: Terminal-Bench 54.2% success rate Near future: Agents handling 80%+ of routine development tasks
Imagine:
Morning standup:
"Hey Gemini, implement the user preferences page we discussed yesterday.
Use the existing auth system, follow our component patterns,
write tests, and submit a PR when ready."
End of day:
PR submitted, tests passing, documentation updated.
Collaborative AI Teams
Multiple AI agents with specialized roles:
Frontend Agent (Gemini 3): Implements UI components
Backend Agent (Gemini 3): Builds APIs and business logic
QA Agent (Gemini 3): Writes and runs comprehensive tests
DevOps Agent (Gemini 3): Handles deployment and monitoring
They communicate and coordinate—AI teammates, not just tools.
Continuous Learning Systems
Your AI pair programmer learns your codebase’s patterns:
# System learns from your code reviews
agent.learn_from_feedback(
pr=pr_number,
feedback="We prefer functional React components",
applies_to="all_future_react_prs"
)
# Future PRs automatically follow your team's preferences
Responsible AI Development: The Serious Stuff
Let’s talk about the elephant in the room. With great power comes great responsibility (yes, Uncle Ben was right).
What You Should Worry About
1. Security Vulnerabilities
AI-generated code can have security flaws. Always:
- Run static analysis tools
- Conduct security reviews
- Never blindly deploy generated code handling sensitive data
2. Bias and Fairness
AI models can perpetuate biases. When building user-facing features:
- Test across diverse user scenarios
- Review AI decisions for fairness
- Implement human oversight for critical decisions
3. Privacy
Never send sensitive data to AI APIs without proper safeguards:
# ❌ Bad
user_data = {
'ssn': '123-45-6789',
'credit_card': '1234-5678-9012-3456'
}
response = model.generate_content(f"Analyze: {user_data}")
# ✅ Good
anonymized_data = {
'has_ssn': True,
'payment_method_type': 'credit_card'
}
response = model.generate_content(f"Analyze: {anonymized_data}")
4. Dependency Risk
Your app shouldn’t completely depend on AI availability:
# Implement fallbacks
try:
ai_result = gemini3.generate(prompt, timeout=5)
except (Timeout, APIError):
# Fall back to rule-based system
fallback_result = traditional_algorithm(input_data)
What Google is Doing
According to their responsible AI documentation, Gemini 3 includes:
- Extensive red-teaming for harmful content
- Bias mitigation in training data
- Safety filters for dangerous requests
- Transparency in model limitations
But remember: responsible use is a partnership between AI provider and developer.
Your Gemini 3 Learning Path
Week 1: Foundations
- Set up Gemini API access
- Complete basic prompt engineering tutorials
- Build a simple chatbot or code assistant
- Project: Personal coding tutor that explains concepts
Week 2: Intermediate Techniques
- Experiment with thinking modes
- Implement tool use for web search and code execution
- Try multimodal inputs (images, documents)
- Project: Automated code reviewer for your repos
Week 3: Advanced Patterns
- Build an agentic workflow
- Optimize for costs and latency
- Implement caching and batching strategies
- Project: Development assistant that helps with debugging
Month 2: Production Systems
- Integrate Gemini 3 into real development workflows
- Set up monitoring and error handling
- Conduct A/B tests on productivity impact
- Project: Team-wide AI pair programming system
Month 3: Innovation
- Explore cutting-edge use cases
- Contribute to open-source AI development tools
- Share learnings with community
- Project: Novel application showcasing Gemini 3 capabilities
Resources for Continued Learning
Official Documentation:
- Gemini API Docs: ai.google.dev/gemini-api
- Thinking Mode Guide: ai.google.dev/gemini-api/docs/gemini-3?thinking=high
- Responsible AI: blog.google/products/gemini/gemini-3/#responsible-development
Community Resources:
- GitHub discussions and sample projects
- Discord/Slack communities for Gemini developers
- Weekly AI development newsletters
Benchmarking Tools:
- HumanEval for code generation testing
- Your own test suites for domain-specific evaluation
- Production metrics dashboards
Conclusion: The AI-Augmented Developer
Here’s the truth: Gemini 3 won’t replace developers. It will create a new category—AI-augmented developers who are 10x more productive than they were before.
Think about it:
- Junior developers learning at senior developer speeds
- Senior developers exploring solutions at research scientist depth
- Teams shipping features in days that previously took weeks
- Code quality improving while development accelerates
The Gemini 3 benchmark numbers aren’t just statistics—they’re a preview of what becomes possible when AI truly thinks alongside humans.
The question isn’t whether to adopt Gemini 3 use in your development workflow. The question is: how quickly can you learn to collaborate with AI before your competitors do?
Start small. Build something useful. Iterate. Learn. And welcome to the future of software development—where the best developers aren’t the ones who memor
Comments