

Claude Opus 4.5 isn’t just another frontier model release — it’s a paradigm shift in how AI handles production-grade software engineering, multi-step agentic workflows, and complex autonomous coding tasks. Released on November 24, 2025, Opus 4.5 reclaims the coding crown with an unprecedented 80.9% score on SWE-bench Verified, while introducing groundbreaking efficiency improvements that slash token usage by up to 76%.
This comprehensive technical analysis explores Opus 4.5’s architecture, benchmark dominance, revolutionary tool-use system, and real-world coding capabilities — all through the lens of developers building production systems.
1. Benchmark Dominance: Opus 4.5 Sets New Standards
SWE-bench Verified: The Gold Standard for Software Engineering
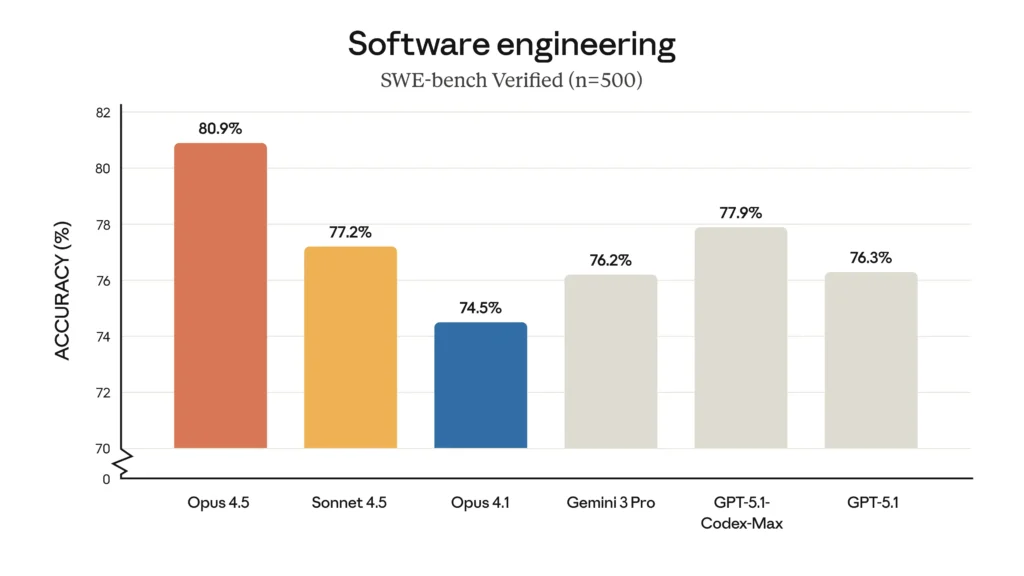
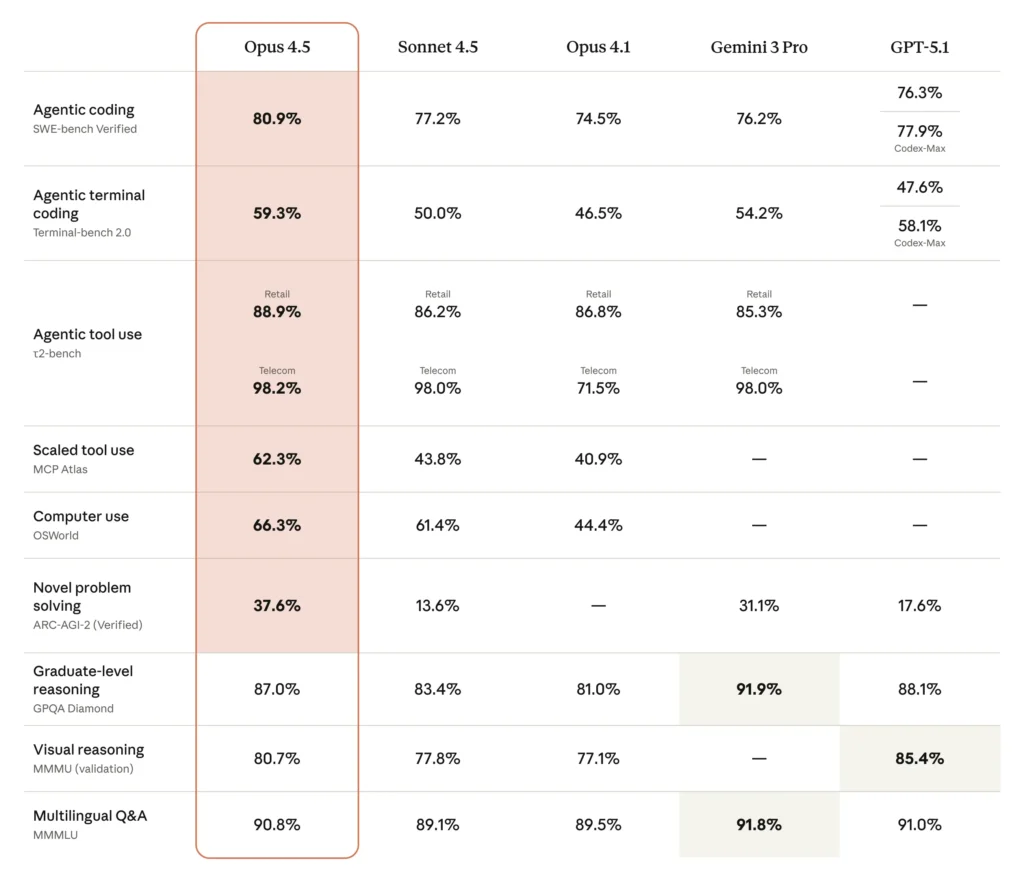
Opus 4.5 achieved 80.9% on SWE-bench Verified, becoming the first model to surpass 80% on this industry-standard benchmark. This performance decisively beats:
- Google Gemini 3 Pro: 76.2%
- OpenAI GPT-5.1-Codex-Max: 77.9%
- Claude Sonnet 4.5: 77.2%
SWE-bench Verified tests real-world software engineering capabilities — not synthetic coding challenges. Each task requires understanding complex codebases, identifying bugs across multiple systems, and implementing fixes that don’t break existing functionality.
What makes this achievement remarkable: Opus 4.5 scored higher than any human candidate on Anthropic’s notoriously difficult engineering take-home exam, demonstrating technical ability and judgment that matches or exceeds senior engineering candidates.
Terminal-bench 2.0: Autonomous Command-Line Mastery
On Terminal-bench 2.0, Opus 4.5 achieved 59.3% — substantially ahead of Gemini 3 Pro’s 54.2% and Sonnet 4.5’s 50.0%. This benchmark tests:
- Repository management and navigation
- Running dev servers and build tools
- Installing dependencies autonomously
- Error tracing and log analysis
- File manipulation and environment setup
- Multi-step debugging workflows
Terminal-bench 2.0 performance directly correlates with how well a model handles autonomous coding agents like Claude Code, Cursor, and Warp.
Multilingual Coding Excellence
Opus 4.5 leads across 7 out of 8 programming languages on SWE-bench Multilingual, demonstrating robust understanding of:
- Python, JavaScript, TypeScript
- Rust, Go, Java
- C++, and functional languages
On Aider Polyglot, Opus 4.5 achieved a 10.6% jump over Sonnet 4.5, proving superior capabilities in complex, multi-language codebases.
Agentic Workflow Benchmarks
tau2-bench (Tool Use Orchestration)
Opus 4.5 achieved 88.9% on retail scenarios and 98.2% on telecom tasks, demonstrating near-perfect multi-tool orchestration. This benchmark tests how well models chain together complex workflows involving multiple API calls, data transformations, and conditional logic.
MCP Atlas (Scaled Tool Use)
Opus 4.5 scored 62.3% on MCP Atlas, significantly outpacing Sonnet 4.5 (43.8%) and Opus 4.1 (40.9%). MCP Atlas tests simultaneous multi-tool usage — the backbone of production agentic systems.
BrowseComp-Plus (Agentic Search)
Opus 4.5 shows significant improvement on frontier agentic search capabilities, enabling autonomous web research, documentation lookup, and information synthesis.
Long-Horizon Task Execution
On Vending-Bench, Opus 4.5 earns 29% more than Sonnet 4.5, demonstrating superior ability to stay on track during extended, multi-step workflows without losing context or making incorrect assumptions.
2. Architectural Innovation: Token Efficiency at Scale
The Efficiency Revolution
Opus 4.5’s most transformative feature isn’t raw intelligence — it’s token efficiency. The model uses dramatically fewer tokens than predecessors to reach similar or better outcomes.
Concrete numbers:
- At medium effort, Opus 4.5 matches Sonnet 4.5’s best SWE-bench score while using 76% fewer output tokens
- At highest effort, Opus 4.5 exceeds Sonnet 4.5 by 4.3 percentage points while using 48% fewer tokens
- Early testers report 50-75% reductions in tool calling errors and build/lint errors
Why efficiency matters in production:
- Cost savings: At scale, 50-70% token reduction translates to massive infrastructure savings
- Faster iteration: Fewer tokens = faster response times = tighter feedback loops
- Extended workflows: More efficient reasoning enables longer autonomous agent runs
- Better context usage: Less verbose reasoning leaves more room for code, documentation, and tool outputs
The Effort Parameter: Precision Control
Opus 4.5 introduces an effort parameter in the API, allowing developers to balance speed, cost, and capability. This gives unprecedented control over computational resource allocation.
Three effort levels:
- Low effort: Conservative token usage, faster responses, suitable for straightforward tasks
- Medium effort: Balanced performance — matches Sonnet 4.5 quality at 76% fewer tokens
- High effort: Maximum capability for complex reasoning, architectural decisions, and multi-system debugging
Real-world application: Developers report that at lower effort, Opus 4.5 delivers the same quality while being dramatically more efficient — exactly what SQL workflows demand.
3. Revolutionary Tool Use Architecture
The Context Window Problem
Traditional AI agents faced a critical limitation: loading dozens of tool definitions consumed tens of thousands of tokens before any actual work began.
The old way: A five-server setup with tools like GitHub, Slack, Sentry, Grafana, and Splunk consumed approximately 55K tokens before the conversation started. Add Jira (17K tokens alone) and you’re approaching 100K+ token overhead.
The impact:
- Reduced effective context window for actual reasoning
- Tool schema confusion when working with 50+ tools
- Slower inference from processing unnecessary tool definitions
- Higher costs from context window bloat
Tool Search Tool: Dynamic Tool Discovery
Instead of loading all tool definitions upfront, the Tool Search Tool discovers tools on-demand, preserving 191,300 tokens of context compared to 122,800 with Claude’s traditional approach — an 85% reduction in token usage.
How it works:
- Developers mark tools with
defer_loading: true - Deferred tools aren’t loaded into context initially
- Claude sees only the Tool Search Tool and critical frequently-used tools
- When needed, Claude searches and loads specific tools dynamically
- Only relevant tool definitions enter the context window
Performance gains: Internal testing showed Opus 4 improved from 49% to 74% on MCP evaluations, and Opus 4.5 improved from 79.5% to 88.1% with Tool Search enabled.
Code example (from AWS Bedrock documentation):
import boto3
import json
# Initialize Bedrock client
session = boto3.Session()
bedrock_client = session.client(
service_name='bedrock-runtime',
region_name='us-east-1'
)
# Define tools with defer_loading enabled
tools = [
{
"name": "get_user_data",
"description": "Retrieves user information",
"input_schema": {...},
"defer_loading": True # Enable tool search
},
{
"name": "update_database",
"description": "Updates database records",
"input_schema": {...},
"defer_loading": True
},
# Core tools remain immediately loaded
{
"name": "search_tools",
"description": "Tool Search Tool",
"defer_loading": False
}
]
Programmatic Tool Calling: Code-Based Orchestration
Programmatic Tool Calling allows Claude to write orchestration code that calls multiple tools, processes outputs, and controls what information enters its context window.
The old way (natural language tool calling):
- Claude requests tool A
- Waits for result, adds to context
- Analyzes result, requests tool B
- Waits for result, adds to context
- Continues for N tools = N inference passes
The new way (programmatic tool calling):
# Claude writes orchestration code
import tools
# Fetch data from multiple sources
user_data = tools.get_user('user_123')
purchase_history = tools.get_purchases(user_data['id'])
recommendations = tools.get_recommendations(purchase_history)
# Process in-memory
filtered_recs = [r for r in recommendations if r['score'] > 0.8]
top_5 = sorted(filtered_recs, key=lambda x: x['score'])[:5]
# Return only final result to context (not intermediate data)
return {
"user_name": user_data['name'],
"recommendations": top_5
}
Advantages:
- Eliminates round-trip inference steps for every tool call
- Processes large datasets (200KB expense data) and returns only final results (1KB)
- Improved accuracy: internal knowledge retrieval went from 25.6% to 28.5%; GIA benchmarks from 46.5% to 51.2%
- When Claude orchestrates 20+ tool calls in a single code block, you eliminate 19+ inference passes
Real-world use case: Claude for Excel uses Programmatic Tool Calling to read and modify spreadsheets with thousands of rows without overloading context.
Tool Use Examples: Pattern-Based Learning
JSON schemas define what’s structurally valid, but they can’t express:
- When to include optional parameters
- Which parameter combinations make sense
- What conventions your API expects
- Real-world usage patterns
Tool Use Examples provide a universal standard for demonstrating correct tool usage through concrete examples — enabling more accurate tool calling for complex nested schemas.
4. Real-World Coding: Production-Grade Examples
Example 1: Multi-Game Arcade Generator (Single-Shot)
One developer demonstrated Opus 4.5’s capabilities by building a complete multi-game arcade in a single prompt through Cursor:
Games included:
- Breakout (paddle physics, brick collision, power-ups)
- Snake (growing tail, self-collision, food spawning)
- Space Invaders (enemy AI, bullet patterns, shields)
- Tetris (rotation logic, line clearing, scoring)
Technical complexity:
- Canvas rendering: Hardware-accelerated 2D graphics
- Game loops: 60 FPS update cycles per game
- Collision detection: Pixel-perfect hit detection across all games
- Particle effects: Explosions, trails, and visual feedback
- Audio system: Sound effects triggered by game events
- Input handling: Keyboard controls with proper event listeners
- State management: Game state, scoring, lives, level progression
- UI rendering: Menu systems, scoreboards, game-over screens
What makes this impressive:
Opus 4.5 didn’t just generate disconnected code snippets. It produced:
- Modular, reusable code structure
- Consistent naming conventions across games
- Proper game loop architecture
- Clean separation of concerns (rendering, logic, input)
- Polished visual design with CSS styling
- Functional audio integration
This demonstrates Opus 4.5’s ability to:
- Maintain long control flows across multiple files
- Write state-heavy code without losing coherence
- Debug autonomously (no manual fixes needed)
- Produce visually polished front-ends
- Understand complex system interactions
Example 2: 3D Lego-Style Voxelizer
Another technical showcase involved building a 3D voxel rendering app with advanced features:
Core functionality:
- User uploads an image
- AI converts it into 3D Lego-style voxel blocks
- Interactive 3D camera with pan/zoom controls
- Spacebar triggers explosion animation
- Blocks scatter realistically then reassemble
- GPU-friendly rendering with smooth 60 FPS
Technical components generated:
- 3D rendering pipeline:
- WebGL/Three.js setup
- Camera controls and transforms
- Lighting and shadow systems
- Image processing algorithms:
- Color quantization (reducing palette to Lego colors)
- Depth estimation from 2D images
- Block generation based on pixel data
- Physics simulation:
- Explosion particle system
- Block scattering with realistic trajectories
- Reassembly animation with easing functions
- Visual effects:
- Shader-like glow effects on blocks
- Smooth camera transitions
- Post-processing effects
- UI/UX design:
- Clean file upload interface
- Intuitive keyboard controls
- Loading indicators and progress feedback
The agentic workflow:
Opus 4.5 didn’t just write code — it executed an autonomous development cycle:
- Planned the application architecture
- Generated all necessary files (HTML, CSS, JS)
- Opened the browser to test
- Loaded sample images for testing
- Captured screenshots of results
- Evaluated visual quality and functionality
- Pressed keyboard shortcuts (spacebar) to test interactions
- Iterated on the implementation
- Improved visual effects and UI polish
- Finalized the production-ready code
This closed-loop workflow — plan, build, test, evaluate, improve — represents genuine autonomous development.
Example 3: Multi-Codebase Refactoring
Opus 4.5 delivered an impressive refactor spanning two codebases and three coordinated agents, developing a robust plan, handling details, and fixing tests.
Real-world scenario:
- Legacy monolith needs microservices extraction
- Shared dependencies across repos
- Must maintain backward compatibility
- All tests must pass post-refactor
What Opus 4.5 handled:
- Analyzing code dependencies across repos
- Planning migration strategy with minimal risk
- Generating new service interfaces
- Updating import paths and references
- Modifying tests to match new architecture
- Coordinating three sub-agents for parallel work
- Verifying integration points
GitHub’s early testing shows Opus 4.5 surpasses internal coding benchmarks while cutting token usage in half, especially well-suited for code migration and refactoring.
5. Deep Agentic Capabilities for Complex Workflows
Multi-Step Planning and Execution
Opus 4.5 excels at breaking down complex objectives into executable steps:
Planning capabilities:
- Task decomposition into subtasks
- Dependency identification between steps
- Risk assessment and mitigation strategies
- Resource allocation across sub-agents
Execution features:
- Sequential task execution with checkpoints
- Parallel workflow coordination
- Automatic retry logic on failures
- Progress monitoring and reporting
Closed-Loop Autonomous Development
Opus 4.5 handles complex workflows with fewer dead-ends, delivering a 15% improvement over Sonnet 4.5 on Terminal Bench.
The closed-loop process:
- Plan: Break down requirements into tasks
- Execute: Write code, modify files
- Test: Run code in browser/terminal
- Observe: Capture screenshots, read logs
- Evaluate: Assess results against requirements
- Iterate: Fix issues, improve implementation
- Finalize: Deliver production-ready code
No human intervention required for:
- Syntax errors and typos
- Logic bugs in algorithms
- UI/UX improvements
- Performance optimizations
- Test failures and fixes
Self-Improving Agents
Rakuten tested Opus 4.5 on office task automation, finding that agents autonomously refined their capabilities — achieving peak performance in 4 iterations while other models couldn’t match that quality after 10.
How it works:
- Agent attempts task with initial approach
- Evaluates results against success criteria
- Identifies failure modes and bottlenecks
- Adjusts strategy and tool usage
- Repeats until optimal performance achieved
The model isn’t updating its own weights but iteratively improving the tools and approaches it uses to solve problems — optimizing skills through practice, like a human developer.
Computer Use: Browser and Terminal Automation
Opus 4.5 is Anthropic’s best computer-using model, reaching 66.3% on OSWorld.
Browser automation capabilities:
- Click UI elements with pixel-perfect accuracy
- Fill forms with contextual understanding
- Execute keyboard shortcuts
- Inspect DOM structure and manipulate elements
- Take screenshots and analyze visual changes
- Navigate multi-page workflows
Terminal automation features:
- Execute shell commands with proper syntax
- Read and interpret terminal output
- Chain commands with pipes and redirects
- Handle environment variables and paths
- Debug errors from stack traces
- Manage git workflows autonomously
Real application: Developers using Cursor, Warp, or Claude Code can delegate entire features to Opus 4.5 — the model handles implementation, testing, and deployment preparation.
6. Claude Code Integration: The Developer’s AI Pair Programmer
Enhanced Plan Mode with Opus 4.5
Claude Code gets an upgrade with Opus 4.5 — Claude asks clarifying questions upfront, then works autonomously.
Plan Mode workflow:
- Requirements gathering: Opus 4.5 asks targeted questions about:
- Technical stack preferences
- Architecture decisions
- Performance requirements
- Integration points
- Testing strategies
- Autonomous execution: After clarification:
- Generates complete project structure
- Implements all features end-to-end
- Writes tests and documentation
- Runs and validates code
- Fixes issues without prompting
- Parallel sessions: Run multiple sessions in parallel: code, research, and update work all at once.
Background Task Execution
Developers can now assign long-running coding tasks and let Opus 4.5 work independently:
- Multi-file refactoring
- Test suite generation
- Documentation writing
- Performance profiling and optimization
- Security audit and vulnerability fixes
Checkpoints feature: Save progress and roll back instantly to previous states — critical for exploratory development and risky refactors.
GitHub Copilot Integration
Early testing shows Opus 4.5 surpasses internal coding benchmarks while cutting token usage in half with GitHub Copilot.
During promotional period (through December 5, 2025), Opus 4.5 rolls out as the default model for Copilot coding agent.
Key advantages:
- Better multi-file context understanding
- More accurate code suggestions
- Stronger architectural reasoning
- Fewer hallucinations in completions
7. Pricing and Accessibility
Dramatic Cost Reduction
Opus 4.5 slashes pricing 66% to $5 per million input tokens and $25 per million output tokens, compared to Opus 4.1’s $15/$75.
Price comparison (per million tokens):
| Model | Input | Output |
|---|---|---|
| Opus 4.5 | $5 | $25 |
| Opus 4.1 | $15 | $75 |
| Sonnet 4.5 | $3 | $15 |
| Haiku 4.5 | $1 | $5 |
| GPT-5.1 | $1.25 | $10 |
| Gemini 3 Pro | $2-4 | $12-18 |
What this means:
- Frontier intelligence at 1/3 the previous cost
- Opus-level capabilities accessible for more use cases
- Competitive with mid-tier models on pricing
- Enterprise-grade AI becomes cost-effective at scale
Platform Availability
Immediate availability:
- Claude.ai (Pro, Max, Team, Enterprise tiers)
- Claude Code (desktop and web)
- Claude API (
claude-opus-4-5-20251101) - AWS Bedrock
- Google Cloud Vertex AI
- Microsoft Azure (via Microsoft Foundry)
- GitHub Copilot (paid plans)
Context window: 200,000 tokens input, 64,000 tokens output
Knowledge cutoff: March 2025 (most recent among Claude 4.5 family)
8. Developer Testimonials: Real-World Impact
Replit
“Opus 4.5 beats Sonnet 4.5 and competition on our internal benchmarks, using fewer tokens to solve the same problems. At scale, that efficiency compounds.” — Michele Catasta, President
Lovable
“Opus 4.5 delivers frontier reasoning within our chat mode where users plan and iterate on projects. Its reasoning depth transforms planning — and great planning makes code generation even better.”
Junie (Coding Agent)
“Based on testing with our coding agent, Opus 4.5 outperforms Sonnet 4.5 across all benchmarks. It requires fewer steps to solve tasks and uses fewer tokens as a result. This indicates the model is more precise and follows instructions more effectively.”
Enterprise SQL Workflows
“The effort parameter is brilliant. Opus 4.5 feels dynamic rather than overthinking, and at lower effort delivers the same quality we need while being dramatically more efficient. That control is exactly what our SQL workflows demand.”
Production Code Review
“We’re seeing 50% to 75% reductions in both tool calling errors and build/lint errors with Opus 4.5. It consistently finishes complex tasks in fewer iterations with more reliable execution.”
Overall Developer Sentiment
“Opus 4.5 is smooth, with none of the rough edges we’ve seen from other frontier models. The speed improvements are remarkable.”
9. Why Developers Choose Opus 4.5
From early access reports and production deployments, developers consistently highlight:
Superior Code Quality
- Clean, modular architecture: Proper separation of concerns
- Consistent naming conventions: Follows language-specific best practices
- Production-ready code: Minimal refactoring needed
- Robust error handling: Anticipates edge cases
Deep Contextual Understanding
- Project-level reasoning: Understands entire codebases, not just files
- Cross-system awareness: Tracks dependencies between components
- Long-term memory: Maintains context across extended sessions
- Opus 4.5 automatically preserves all previous thinking blocks throughout conversations, maintaining reasoning continuity
Reliable Execution
- Fewer hallucinations: More accurate code generation
- Better debugging: Identifies root causes faster
- Excellent tool integration: Seamless MCP server usage
- Multi-step problem solving: Handles complex, ambiguous requirements
Architectural Excellence
- Strong system design: Makes sound architectural decisions
- Early testers consistently describe the model as able to interpret ambiguous requirements, reason over architectural tradeoffs, and identify fixes for issues spanning multiple systems
- Security awareness: Enhanced security engineering with more robust security practices and vulnerability detection
10. Advanced Features for Production Systems
Extended Thinking
Claude Sonnet 4.5 performs significantly better on coding tasks when extended thinking is enabled. Extended thinking allows models to:
- Explore multiple solution approaches internally
- Reason through complex tradeoffs
- Catch potential bugs before generating code
- Optimize algorithms before implementation
Infinite Chat Conversations
In Claude apps, lengthy conversations no longer hit a wall. Claude automatically summarizes earlier context, allowing conversations to continue endlessly.
Technical implementation:
- Automatic context compaction when approaching limits
- Intelligent summarization preserving key details
- Seamless continuation without losing thread
Impact for developers:
- Long-running agent sessions (8+ hours)
- Extended debugging conversations
- Multi-day project development
- Continuous context across iterations
Memory and Context Management
Opus 4.5 comes with memory improvements for long-context operations, requiring significant changes in how the model manages memory.
“This is where fundamentals like memory become really important, because Claude needs to be able to explore code bases and large documents, and also know when to backtrack and recheck something” — Penn, Anthropic
Key capabilities:
- Working memory tracking: Claude Haiku 4.5 features context awareness, enabling the model to track its remaining context window throughout conversations
- Better task persistence: Models understand available working space
- Multi-context-window workflows: Improved handling of state transitions across extended sessions
Multi-Agent Orchestration
Opus 4.5 is very effective at managing a team of subagents, enabling construction of complex, well-coordinated multi-agent systems.
Architecture pattern:
- Lead agent (Opus 4.5): High-level planning, coordination
- Sub-agents (Haiku 4.5): Specialized tasks, parallel execution
- Communication layer: State sharing, task delegation
- Monitoring: Progress tracking, error handling
Use cases:
- Full-stack software engineering (frontend + backend + database agents)
- Cybersecurity workflows (reconnaissance, analysis, remediation agents)
- Financial modeling (data collection, analysis, reporting agents)
- DevOps automation (deployment, monitoring, incident response agents)
11. Safety and Reliability
Prompt Injection Resistance
Opus 4.5 is harder to trick with prompt injection than any other frontier model in the industry.
On standardized prompt injection benchmarks (developed by Gray Swan):
- Single attack attempts: ~5% success rate (95% blocked)
- Ten different attacks: ~33% success rate
What this means:
- Stronger protection against malicious inputs
- More reliable behavior in production
- Better compliance with security policies
- Reduced risk of jailbreaks
Caveat: Training models not to fall for prompt injection still isn’t sufficient — applications should be designed under the assumption that sufficiently motivated attackers will find ways to trick models.
Production Testing and Validation
Extensive testing and evaluation — conducted in partnership with external experts — ensures Opus 4.5 meets Anthropic’s standards for safety, security, and reliability.
The accompanying model card covers:
- Safety evaluation results in depth
- Potential failure modes
- Recommended usage guidelines
- Known limitations
12. Performance Across All Domains
While Opus 4.5 excels at coding, it’s a frontier model across all capabilities:
Vision and Multimodal Understanding
Opus 4.5 doubles down as Anthropic’s best vision model, unlocking workflows depending on complex visual interpretation and multi-step navigation.
On MMMU (multimodal understanding combining visual and textual reasoning), Opus 4.5 achieves 80.7%.
Advanced Reasoning
On GPQA Diamond (graduate-level reasoning across physics, chemistry, biology), Opus 4.5 scores 87.0%.
On ARC-AGI-2 (novel problem-solving that can’t be memorized from training), Opus 4.5 achieves 37.6% — testing genuine out-of-distribution reasoning.
Multilingual Capabilities
On MMMLU (multilingual question answering), Opus 4.5 scores 90.8%, demonstrating strong understanding across multiple languages.
Enterprise Productivity
For knowledge workers, Opus 4.5 delivers a step-change improvement in powering agents that create spreadsheets, presentations, and documents.
Capabilities:
- Excel: Support for pivot tables, charts, and file uploads
- PowerPoint: Slide creation with professional polish
- Word: Document generation with domain awareness
- Chrome: Web automation and research
13. Ideal Use Cases for Opus 4.5
Based on benchmarks, features, and real-world testing:
1. Professional Software Engineering
- Complex, multi-file refactoring projects
- Legacy system modernization
- Microservices architecture design
- Full-stack application development
- Code migration between languages/frameworks
2. Autonomous Coding Agents
- Long-horizon development tasks (4+ hours)
- Multi-repository coordination
- Continuous integration/deployment automation
- Automated code review and security audits
- Self-improving agent systems
3. Enterprise Workflows
- Complex enterprise tasks combining information retrieval, tool use, and deep analysis
- Financial modeling and forecasting
- Business intelligence report generation
- Spreadsheet-heavy data analysis
- Document and presentation creation
4. Advanced Tool Orchestration
- Systems requiring 20+ tool integrations
- Complex API workflow automation
- Multi-step research and synthesis
- Cross-platform automation
- MCP server-powered applications
5. Computer Use Applications
- Desktop task automation
- Browser-based workflow automation
- UI testing and validation
- Screenshot-driven debugging
- Multi-application coordination
14. When to Use Each Claude 4.5 Model
Opus 4.5: Maximum Intelligence
Best for:
- Complex specialized tasks requiring deep reasoning
- Multi-step agentic workflows with 10+ tool calls
- Production-grade software engineering projects
- Complex refactoring across multiple codebases
- Advanced financial modeling and analysis
- Long-horizon autonomous agent tasks
- Tasks where accuracy matters more than speed
- Enterprise workflows requiring frontier intelligence
Token efficiency: 48-76% fewer tokens than previous models for equivalent quality
Pricing: $5 input / $25 output per million tokens
Sonnet 4.5: Balanced Performance
Best for:
- Most everyday coding tasks
- Rapid prototyping and iteration
- General-purpose development
- Documentation generation
- Standard API integrations
- Chat-based assistance
- Cost-sensitive applications requiring strong performance
Pricing: $3 input / $15 output per million tokens
Haiku 4.5: Speed and Efficiency
Best for:
- High-volume, straightforward tasks
- Real-time applications requiring sub-second latency
- Simple code generation and completion
- Log analysis and parsing
- Batch processing pipelines
- Sub-agent execution in multi-agent systems
- Applications where speed is critical
Pricing: $1 input / $5 output per million tokens
15. The Future: Towards Autonomous Software Engineering
Current State: AI as Senior Pair Programmer
Opus 4.5 represents a fundamental shift in developer-AI collaboration. It’s no longer just an autocomplete tool or code snippet generator — it’s a capable engineering colleague that can:
- Understand ambiguous requirements and ask clarifying questions
- Make sound architectural decisions with proper tradeoff analysis
- Write production-grade code with minimal supervision
- Debug complex multi-system issues autonomously
- Execute multi-day development projects end-to-end
- Coordinate multiple sub-agents for parallel workflows
Emerging Capabilities
Self-improving agents: Rakuten’s testing shows agents that autonomously refine their approach, reaching peak performance in 4 iterations — demonstrating genuine learning through practice.
Multi-agent orchestration: Opus 4.5’s ability to manage teams of specialized sub-agents enables enterprise-scale automation previously requiring human coordination.
Closed-loop development: Plan → Build → Test → Evaluate → Iterate cycles happening autonomously, with human oversight only at major checkpoints.
What’s Next?
We’re approaching a future where:
- AI handles entire features: From requirements to deployment
- Humans focus on strategy: Product direction, not implementation details
- Development velocity increases 10x: Ship in days what took months
- Code quality improves: Consistent patterns, comprehensive tests, thorough documentation
- Technical debt decreases: Continuous refactoring and modernization
But we’re not there yet. Current limitations include:
- Long-horizon reliability (24+ hour autonomous projects)
- Novel algorithm development requiring research
- Complex system design requiring domain expertise
- Understanding deeply specialized technical domains
- Making business/product decisions
Opus 4.5 is one of the strongest steps toward fully autonomous software engineering — but the journey continues.
16. Best Practices for Using Opus 4.5
Getting Maximum Value
1. Leverage the effort parameter
# For exploratory work, use medium effort
response = anthropic.messages.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": prompt}],
metadata={"thinking_budget_tokens": 10000} # Medium effort
)
# For critical production code, use high effort
response = anthropic.messages.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": prompt}],
metadata={"thinking_budget_tokens": 30000} # High effort
)
2. Enable Tool Search for large tool sets
tools = [
{
"name": "github_search",
"description": "Search GitHub repositories",
"defer_loading": True # Only load when needed
},
{
"name": "slack_send",
"description": "Send Slack messages",
"defer_loading": True
}
]
3. Use Programmatic Tool Calling for complex workflows
# Instead of 10+ sequential tool calls, let Opus orchestrate
tools = [{
"name": "execute_python",
"description": "Run Python code with access to all tools",
"capabilities": ["fetch_data", "process", "analyze", "report"]
}]
4. Provide Tool Use Examples for complex APIs
tool_definition = {
"name": "update_database",
"examples": [
{
"input": {"user_id": 123, "fields": {"status": "active"}},
"description": "Update single field"
},
{
"input": {"user_id": 123, "fields": {"status": "active", "tier": "premium"}},
"description": "Update multiple fields atomically"
}
]
}
5. Break down mega-projects into milestones
Even with Opus 4.5’s long-context capabilities, structured projects work better:
- Define clear milestones with acceptance criteria
- Let Opus plan the approach for each milestone
- Execute autonomously with checkpoints
- Review and iterate before moving to next milestone
Prompting Tips for Developers
Be specific about technical constraints:
Build a real-time chat application using:
- WebSocket connections (not polling)
- React 18 with concurrent features
- Redis for message queuing
- JWT authentication
- TypeScript strict mode
- Must handle 10k concurrent connections
Specify quality requirements:
Generate production-grade code with:
- Comprehensive error handling
- Input validation and sanitization
- Security best practices (no SQL injection, XSS protection)
- Unit tests with >90% coverage
- JSDoc comments for all public functions
- Performance considerations (O(n) or better)
Use iterative refinement:
First pass: Build the core functionality
Second pass: Add error handling and edge cases
Third pass: Optimize performance
Fourth pass: Add comprehensive tests
Leverage autonomous workflows:
Your task: Modernize our legacy authentication system
Requirements:
- Migrate from cookies to JWT
- Add refresh token rotation
- Implement rate limiting
- Update all 15 microservices
- Maintain backward compatibility during transition
- Write migration guide
Work autonomously. Test each service after migration.
Ask clarifying questions before you begin.
17. Learning Resources and Documentation
Official Documentation
Anthropic Developer Documentation:
- API reference: https://docs.anthropic.com/en/api
- Prompt engineering guide: https://docs.anthropic.com/en/docs/build-with-claude/prompt-engineering
- Tool use documentation: https://docs.anthropic.com/en/docs/build-with-claude/tool-use
- Computer use guide: https://docs.anthropic.com/en/docs/build-with-claude/computer-use
Claude Code Documentation:
- Getting started: https://claude.ai/code
- Best practices for agentic workflows
- Integration with VS Code, Cursor, and other IDEs
Model Cards:
- Opus 4.5 model card (detailed capabilities, limitations, safety evaluations)
- Benchmark methodology and results
Developer Community
Early Access Feedback:
- Replit, Lovable, Junie, Rakuten, and GitHub have shared real-world testing results
- Developer testimonials highlight practical use cases
- Community-driven benchmarks and comparisons
Integration Examples:
- AWS Bedrock integration guides
- Google Cloud Vertex AI setup
- Microsoft Azure Foundry configuration
- GitHub Copilot integration
18. Benchmark Summary: Complete Performance Profile
Coding and Software Engineering
| Benchmark | Score | Context |
|---|---|---|
| SWE-bench Verified | 80.9% | Real-world software engineering tasks |
| Terminal-bench 2.0 | 59.3% | Autonomous command-line operations |
| SWE-bench Multilingual | Leader in 7/8 languages | Multi-language coding proficiency |
| Aider Polyglot | 10.6% jump vs Sonnet 4.5 | Complex multi-language codebases |
Tool Use and Agentic Workflows
| Benchmark | Score | Context |
|---|---|---|
| tau2-bench (Retail) | 88.9% | Multi-tool orchestration |
| tau2-bench (Telecom) | 98.2% | Complex workflow execution |
| MCP Atlas | 62.3% | Scaled simultaneous tool use |
| BrowseComp-Plus | Frontier performance | Agentic web search and research |
| Vending-Bench | 29% more than Sonnet 4.5 | Long-horizon task persistence |
Computer Use and Automation
| Benchmark | Score | Context |
|---|---|---|
| OSWorld | 66.3% | Browser and desktop automation |
Reasoning and Intelligence
| Benchmark | Score | Context |
|---|---|---|
| GPQA Diamond | 87.0% | Graduate-level scientific reasoning |
| ARC-AGI-2 | 37.6% | Novel problem-solving |
| MMMU | 80.7% | Multimodal understanding |
| MMMLU | 90.8% | Multilingual capabilities |
19. Conclusion: A New Era of AI-Powered Development
Claude Opus 4.5 represents more than incremental improvement — it’s a fundamental leap in what AI can achieve in software engineering and autonomous workflows.
Key Takeaways
Performance leadership: 80.9% on SWE-bench Verified establishes Opus 4.5 as the world’s most capable coding model, surpassing human engineering candidates on internal evaluations.
Revolutionary efficiency: 48-76% token reduction while maintaining or exceeding quality makes frontier intelligence economically viable at scale.
Agentic autonomy: Closed-loop workflows, self-improving agents, and multi-agent orchestration enable truly autonomous development pipelines.
Production-ready tooling: Tool Search Tool, Programmatic Tool Calling, and Tool Use Examples solve the practical challenges that limited previous AI coding assistants.
Accessible pricing: 66% price reduction ($5/$25 per million tokens) democratizes access to frontier AI capabilities.
The Developer Impact
For software engineers, Opus 4.5 changes the equation:
Before: AI assists with snippets, autocomplete, and simple functions
Now: AI handles entire features, complex refactoring, and multi-day projects
Before: Developers write code, AI suggests improvements
Now: Developers define requirements, AI architects and implements solutions
Before: AI tool use limited by context overhead
Now: AI dynamically discovers and orchestrates 100+ tools efficiently
Before: Multi-agent systems require complex orchestration frameworks
Now: Opus 4.5 natively coordinates specialized sub-agents
What This Means for the Industry
We’re witnessing the emergence of AI as colleague, not just assistant:
- Startups can build with small teams what previously required dozens of engineers
- Enterprises can modernize legacy systems without massive rewrites
- Individual developers can ship production applications in days, not months
- Engineering teams can focus on architecture and product strategy while AI handles implementation
The Road Ahead
Opus 4.5 is a milestone, not a destination. Current limitations remain:
- Novel algorithm research requiring deep domain expertise
- 24+ hour fully autonomous projects without human oversight
- Understanding highly specialized technical domains
- Making product and business decisions requiring human judgment
But the trajectory is clear: AI is rapidly becoming capable of handling increasingly complex, creative, and autonomous software engineering tasks.
Getting Started Today
For individual developers:
- Try Opus 4.5 in Claude Code or via API
- Start with well-defined features or refactoring tasks
- Gradually increase autonomy as you build trust
- Experiment with extended thinking and effort parameters
For teams:
- Identify high-value, time-consuming tasks (migrations, refactoring, documentation)
- Pilot Opus 4.5 on non-critical projects first
- Establish checkpoints and review processes
- Scale successful workflows across the organization
For enterprises:
- Assess current development bottlenecks
- Design agent workflows with Opus 4.5 coordination
- Implement Tool Search and Programmatic Tool Calling
- Monitor token efficiency and cost savings
- Iterate on prompts and agent designs
Additional Resources
Access Opus 4.5
- Claude.ai: https://claude.ai (Pro, Max, Team, Enterprise)
- Claude API: Model ID
claude-opus-4-5-20251101 - Claude Code: https://claude.ai/code (desktop and web)
- AWS Bedrock: Available in supported regions
- Google Cloud Vertex AI: Available now
- Microsoft Azure: Via Microsoft Foundry
- GitHub Copilot: Available to paid subscribers
Stay Updated
- Anthropic News: https://www.anthropic.com/news
- API Changelog: https://docs.anthropic.com/en/release-notes
- Developer Discord: Community discussions and support
- Research Papers: Detailed technical deep-dives
Final Thoughts
Opus 4.5 isn’t just another model release — it’s a statement about the future of software development.
For the first time, we have an AI model that:
- Matches or exceeds human engineering candidates on complex tasks
- Operates with frontier intelligence at economically viable prices
- Handles truly autonomous multi-day development projects
- Coordinates teams of specialized AI agents
- Writes production-grade code with minimal supervision
The era of AI-assisted development is giving way to AI-autonomous development.
The question is no longer “Can AI help me code?” but “What should I build now that AI can handle the implementation?”
Welcome to the future of software engineering. Welcome to Opus 4.5.
Comments