

Introduction: Why Speech Recognition Matters
In the modern world, speech is one of the most natural ways for humans to communicate. From smart assistants and voice-controlled devices to podcasts, customer support, and multilingual accessibility — speech is everywhere. Yet for machines, understanding spoken language accurately has always been a challenge.
This is where OpenAI Whisper steps in. Whisper is not just another speech recognition tool — it’s a multilingual, multitask model that brings the power of deep learning to real-world audio processing. It can transcribe, translate, and understand speech in a wide range of languages and conditions, all through a single API call.
For developers, Whisper opens new opportunities to build voice-enabled applications, AI assistants, media tools, and multilingual communication platforms with minimal effort.
What Is OpenAI Whisper?
OpenAI Whisper is an Automatic Speech Recognition (ASR) model developed by OpenAI, trained on an enormous dataset of 680,000 hours of multilingual and multitask data.
This data was collected from diverse sources across the web, covering multiple languages, accents, noise levels, and speaking styles. The result is an AI model that can understand speech far more robustly than traditional systems.
Whisper isn’t limited to English — roughly one-third of its training data was in non-English languages. It can transcribe speech in many languages and even translate them into English, making it a global tool for voice applications.
How Whisper Works: The Architecture Explained Simply
The Whisper architecture is based on a Transformer — the same type of model that powers GPT and other state-of-the-art language models. But instead of processing text as input, Whisper takes audio signals.
Let’s simplify the process step by step.
1. Audio Input
The model starts with your audio file — this could be in MP3, WAV, or other formats supported by the OpenAI API. The audio is first split into 30-second segments to make processing manageable.
2. Feature Extraction – Log-Mel Spectrogram
Each segment is converted into a log-Mel spectrogram, which is a visual representation of sound. You can think of this as turning sound waves into an image that captures frequency and intensity over time.
3. Encoder – Listening and Understanding
The encoder takes the spectrogram and processes it using layers of self-attention to capture contextual patterns — for example, tone, pitch, or phonetic relationships between sounds.
4. Decoder – Generating Text
The decoder then predicts the text tokens that match the audio input. It works like GPT but focuses on converting sound into words instead of generating free-form language.
Diagram 1: Whisper Architecture (simplified explanation)
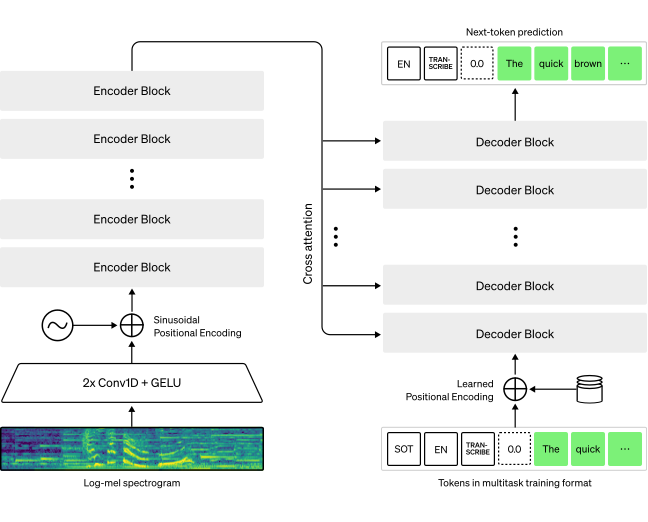
- Audio → Log-Mel Spectrogram → Encoder → Decoder → Text
- The decoder uses special control tokens to perform specific tasks:
<|translate|>– for translating speech to English<|transcribe|>– for transcription in the original language<|timestamp|>– for phrase-level timing<|language|>– for language identification
This end-to-end approach allows Whisper to handle multiple tasks using one unified architecture.
The Approach: Why Whisper Is So Robust
Traditional ASR systems are often fine-tuned for specific datasets, languages, or environments. They may work perfectly on clean, studio-recorded English audio but fail when given real-world samples like a YouTube video, a noisy phone call, or a multilingual meeting.
OpenAI Whisper takes a different approach.
It was trained on a massive and diverse dataset, containing real-world recordings in multiple languages and acoustic conditions. This diversity helps Whisper generalize well, meaning it performs consistently even on challenging or unseen audio.
Diagram 2: Whisper Approach (simplified)

- Input audio in any language → Whisper model → Transcription or Translation output
- The model alternates between transcription and translation tasks during training, making it fluent in both.
This design gives Whisper an advantage:
- It’s multilingual (understands many languages).
- It’s robust (handles noise, accents, background sounds).
- It’s general-purpose (works without task-specific tuning).
In short, Whisper doesn’t just recognize words — it understands the sound of human speech in context.
The ASR Details: Whisper’s Secret Sauce
Whisper is an encoder-decoder Transformer model, but with custom features that make it ideal for audio processing. Here are some of the technical details explained simply:
1. Data Diversity
Whisper’s training data includes podcasts, videos, lectures, and multilingual recordings. This variety ensures it doesn’t overfit to one kind of audio.
2. Multitask Training
During training, Whisper is alternately tasked with:
- Transcribing audio in its original language.
- Translating non-English audio into English.
This makes Whisper both a transcription and a translation model — a two-in-one design.
3. Zero-Shot Performance
Even though Whisper was not fine-tuned on specific benchmarks like LibriSpeech, it still performs well on them in zero-shot mode (without any retraining).
It makes 50% fewer errors on diverse datasets compared to previous models.
Diagram 3: ASR Details (explained)
Shows how the model processes input in multiple tasks, predicting timestamps, text, and language simultaneously.
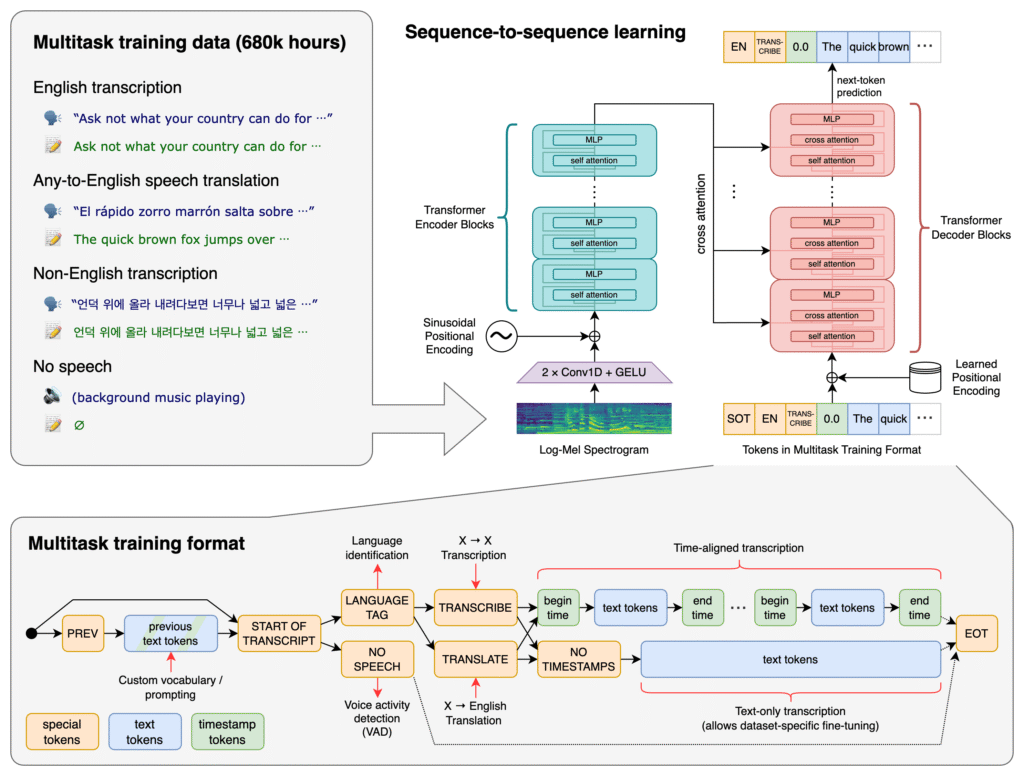
This combination of large-scale training, multilingual exposure, and multitask objectives gives Whisper unmatched versatility.
OpenAI Whisper Python Example: How Developers Can Use It
Using OpenAI Whisper in Python is incredibly simple. The OpenAI API provides easy-to-use methods for transcription and translation.
Here’s a basic example:
import openai
openai.api_key = "YOUR_API_KEY"
audio_file = open("audio_sample.mp3", "rb")
# Transcribe the audio
transcription = openai.Audio.transcriptions.create(
model="whisper-1",
file=audio_file
)
print(transcription.text)
Translation Example
If you want to translate speech in another language (say French or Hindi) into English:
translation = openai.Audio.translations.create(
model="whisper-1",
file=open("foreign_audio.mp3", "rb")
)
print(translation.text)
Why Developers Love Whisper
- Works out of the box — no model training needed.
- Handles multiple formats:
.mp3,.mp4,.wav,.m4a,.webm, etc. - Built for scalability via the OpenAI API.
- Integrates easily with frameworks like Flask, FastAPI, or Django for web apps.
For developers, OpenAI Whisper Python integration makes it effortless to add voice functionality to applications.
OpenAI Whisper Pricing Explained
Let’s talk about OpenAI Whisper pricing — one of the reasons it’s so popular.
As of the latest update (check OpenAI’s official pricing page, Whisper costs around:
$0.006 per minute of audio.
That means you can transcribe:
- 1 minute of audio → $0.006
- 1 hour of audio → $0.36
- 10 hours of audio → $3.60
This makes Whisper far more affordable than most commercial transcription services, which can charge anywhere from $1 to $3 per minute.
Cost Efficiency in Practice
Let’s say you’re building a podcast transcription app:
- 100 users upload 30-minute episodes weekly → 50 hours total.
- Total cost using Whisper = 50 × $0.006 × 60 = $18 per week for all users.
That’s incredibly cost-effective for startups, educators, and developers building SaaS tools.
Real-World OpenAI Whisper Use Cases
Developers around the world are already integrating Whisper into all kinds of projects. Here are some examples:
1. Podcast Transcription Tools
Convert podcast episodes into searchable text for SEO, captions, or blog content.
2. Automatic Subtitles for Videos
Add Whisper to video platforms or editing software to generate accurate subtitles in multiple languages.
3. Meeting Note Automation
Integrate Whisper into conferencing tools (like Zoom or Meet) to create instant meeting summaries.
4. Language Translation Services
Use Whisper’s translation mode to turn foreign-language audio into English — ideal for global media or education platforms.
5. Developer Assistants
Voice-to-code tools can use Whisper to let developers dictate commands or code snippets verbally.
6. Mobile Accessibility
Build apps that transcribe speech for the hearing-impaired or translate conversations on the go.
These OpenAI Whisper use cases showcase the model’s flexibility across industries — from education and media to accessibility and AI-driven automation.
How Developers Can Build With Whisper
Here’s a sample workflow for integrating Whisper into a real-world project:
- Collect audio input — from mic, uploaded files, or recorded calls.
- Send to OpenAI API using the
/v1/audio/transcriptionsor/v1/audio/translationsendpoint. - Store results in your database or file system.
- Display transcripts in a UI or process them further (e.g., summarization with GPT-4).
You can even chain Whisper with GPT models to build advanced workflows like:
- “Transcribe + summarize meeting”
- “Translate + generate subtitles”
- “Voice input + chatbot response”
This multi-model integration makes OpenAI’s ecosystem incredibly powerful.
Model Performance and Limitations
Whisper performs remarkably well, but like all AI systems, it has some limitations:
| Strengths | Limitations |
|---|---|
| Works in 90+ languages | Not real-time (yet) |
| Handles noise & accents | May hallucinate words on poor audio |
| High transcription accuracy | Larger model = slower inference |
| Supports timestamps & language ID | Requires good audio quality for best results |
Despite these, developers find Whisper more robust than many commercial ASR APIs due to its open-source transparency and consistent performance.
Whisper vs Traditional ASR Systems
| Feature | Traditional ASR | OpenAI Whisper |
|---|---|---|
| Training Data | Narrow, domain-specific | 680,000 hours diverse audio |
| Languages | Often English only | Multilingual (90+) |
| Noise Handling | Sensitive | Robust |
| Translation | Separate model needed | Built-in |
| Open Source | Usually closed | Open and free for research |
| Integration | Platform-dependent | Simple API & Python SDK |
Whisper’s open-source foundation also allows developers to run it locally (for privacy or offline scenarios) using the official GitHub repository:
https://github.com/openai/whisper
Whisper Models and Sizes
Whisper comes in different model sizes, allowing you to trade off speed for accuracy:
| Model | Size | Speed | Accuracy |
|---|---|---|---|
tiny | 39M | Fastest | Lower |
base | 74M | Fast | Moderate |
small | 244M | Medium | Good |
medium | 769M | Slower | Very good |
large | 1550M | Slowest | Best accuracy |
For most API use cases, whisper-1 (based on the large model) offers the best results.
For local inference, smaller models can be used when speed or device constraints matter.
Privacy, Security, and Data Use
Developers often ask how Whisper handles data.
When using the OpenAI API, your audio is transmitted securely, and per OpenAI’s policy, data from API usage isn’t used to train future models (unless you explicitly allow it).
If you need full privacy, you can:
- Run the open-source Whisper model locally.
- Store transcripts only on your secure servers.
- Use encrypted connections for uploads.
This flexibility makes Whisper suitable even for sensitive industries like healthcare, law, or education.
Performance Benchmarks
Whisper’s performance has been benchmarked against standard datasets such as LibriSpeech, TED-LIUM, and Common Voice.
In zero-shot mode, it achieves:
- WER (Word Error Rate) of ~5.8% on clean English speech.
- Consistent performance across 90+ languages.
- Outperforms supervised models on multilingual translation tasks.
This combination of accuracy, robustness, and ease of use explains why developers globally are adopting it.
The Future of Whisper and Speech AI
OpenAI’s Whisper has already set a new standard for open-source ASR. But the future holds even more potential:
- Real-time transcription for live events.
- Integration with GPT models for “listen-and-respond” conversational AI.
- Language expansion beyond current datasets.
- Smaller, edge-optimized models for mobile devices.
With OpenAI continuously improving its ecosystem, we can expect Whisper to evolve into the backbone of next-generation voice interfaces.
Conclusion
OpenAI Whisper is more than a speech recognition tool — it’s a developer’s gateway to voice-enabled AI.
Built on a massive multilingual dataset and a Transformer architecture, Whisper is powerful, accurate, and surprisingly easy to use.
Whether you’re:
- Building a podcast transcription tool,
- Adding voice commands to your app, or
- Automating translation across languages,
Whisper delivers scalable, affordable, and high-quality results.
It’s open-source, API-accessible, and available globally — making it one of the most practical AI tools for developers in 2025 and beyond.
Comments