

Key Takeaways (2-Minute Read)
- DeepSeek 3.2 is an open-source AI model family rivaling GPT-5 and Gemini 3.0 Pro
- Three variants: Base (balanced), Exp (efficiency-focused), Speciale (max reasoning power)
- Gold-medal performance at IMO 2025 and IOI 2025 math/coding competitions
- MIT-licensed and free to use commercially
- Up to 70% cheaper inference costs with new sparse attention technology
Type “deepseek 3.2” into Google and you instantly see what people care about:
“deepseek 3.2 exp”, “deepseek 3.2 speciale”, “deepseek 3.2 benchmark”, “pricing”, “vs GPT-5”, “reddit”…
That’s because DeepSeek 3.2 isn’t just another model drop. It’s the moment open-source AI seriously crashes the GPT-5 / Gemini 3.0 Pro party.
In this post, we’ll break down:
- What Deepseek 3.2 actually is
- The differences between the three model variants
- The key benchmarks (including those gold-medal math scores)
- Why its sparse attention and RL training approach are a big deal
- How you can start using or hosting it yourself
What is Deepseek 3.2?
Deepseek 3.2 is the latest flagship family of large language models from Chinese AI lab DeepSeek.
It’s built on their V3 MoE (mixture-of-experts) architecture, scaled up to:
- 685B total parameters, with 671B in the main model and 37B “active” parameters used per token at inference
- 128K context length, optimized for long-context reasoning and agent workflows
Unlike many frontier models, Deepseek 3.2 is open-weight and MIT-licensed.
This means you can download the weights, modify them, and use them commercially with very light restrictions. Read more about Deepseek 3.2’s official launch and details here.
And performance-wise?
DeepSeek explicitly positions V3.2 as “your daily driver at GPT-5-level performance,” with the high-compute variant V3.2-Speciale rivalling Gemini 3.0 Pro on reasoning tasks.
The Deepseek 3.2 Family: Which Model Should You Use?
Let’s untangle the three names you’ll see everywhere: deepseek 3.2, deepseek 3.2 exp, and deepseek 3.2 speciale.
Comparison Table: Base vs Exp vs Speciale
| Feature | Deepseek 3.2 (Base) | Deepseek 3.2 Exp | Deepseek 3.2 Speciale |
|---|---|---|---|
| Best For | General daily use | Cost efficiency & throughput | Research-grade reasoning |
| Attention Type | Standard dense | Sparse (DSA) | Dense with extended compute |
| Cost | Balanced | 50-70% cheaper | Higher (more tokens used) |
| Speed | Fast | Fastest | Slower (deep reasoning) |
| Use Cases | Chatbots, coding, agents | Long-context apps, high-volume | Math proofs, competitive programming |
| Tool Use | Full support | Full support | Not available (benchmark mode) |
| Availability | API + Open weights | API + Open weights | API only |
1. Deepseek 3.2 (The Balanced “Daily Driver”)
This is the “main” model most people will use.
Goal: Balance cost, speed and quality
Strengths:
- General chat and instruction following
- Coding assistance and debugging
- Multi-turn reasoning
- Long-context work
- Agent and tool use
Positioning: DeepSeek describes it as GPT-5-class performance, but with better efficiency and full open access.
For most applications—chatbots, developer copilots, research assistants—this is the version you’d likely standardize on.
2. Deepseek 3.2 Exp (The Experimental Efficiency Monster)
Deepseek 3.2 Exp is an experimental branch built specifically to prove out a new attention mechanism called DeepSeek Sparse Attention (DSA).
Key innovation:
Instead of every token looking at every other token (which gets expensive fast), DSA lets each token selectively focus on:
- A local window of nearby tokens
- A small set of global “important” tokens
- Some long-range links for structure
Real-world impact:
Long-context inference can be 50–70% cheaper while maintaining almost identical quality to V3.1-Terminus, the previous flagship.
When to use Exp:
If you care about throughput, tokens per dollar, or building huge-context applications, this is the variant to watch.
Where to find it:
- On Hugging Face as
deepseek-ai/DeepSeek-V3.2-Expand related base models - On providers like Together and OpenRouter, which let you hit it via API without running 600+ GB of weights yourself
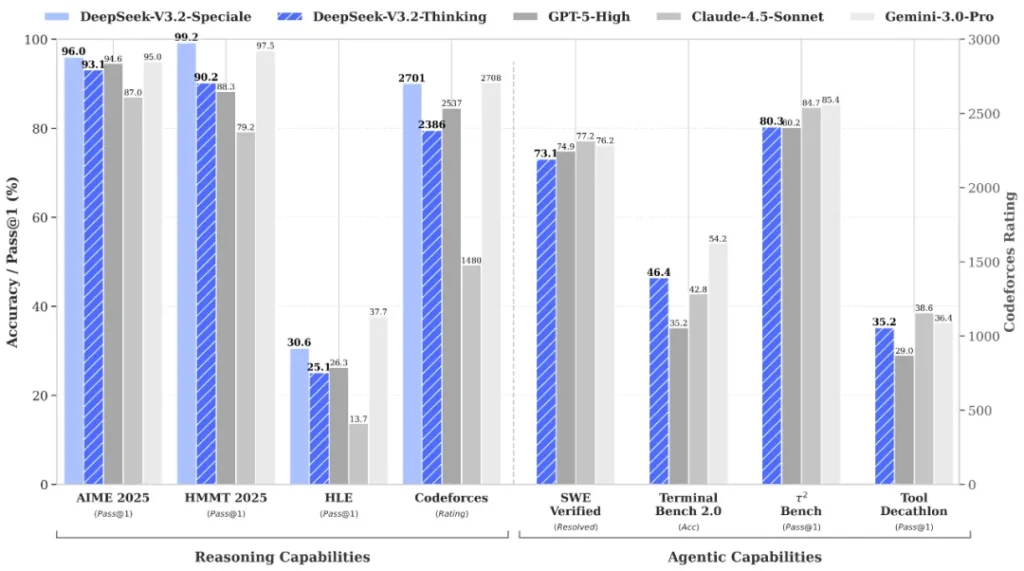
3. Deepseek 3.2 Speciale (The Max-Compute Reasoning Beast)
Then there’s deepseek 3.2 speciale—the one everyone screenshots.
This variant dials everything up for pure reasoning power.
High-compute “thinking” mode:
It uses many more tokens to reason step-by-step before answering, similar to OpenAI’s o1 model approach.
Benchmark results:
- Gold-level performance at IMO 2025 (35/42 score) and IOI 2025 (492/600)
- Competitive with GPT-5-High on complex coding challenges
- Exceptional at mathematical proofs and competitive programming
The catch:
Speciale burns more tokens per answer and is currently API-only with no tool use (for clean benchmarking).
When to use Speciale:
If you’re doing research-grade reasoning, theorem proving, or hardcore competitive coding, this is the model you throw at the problem.
Visit the official Hugging Face link here.
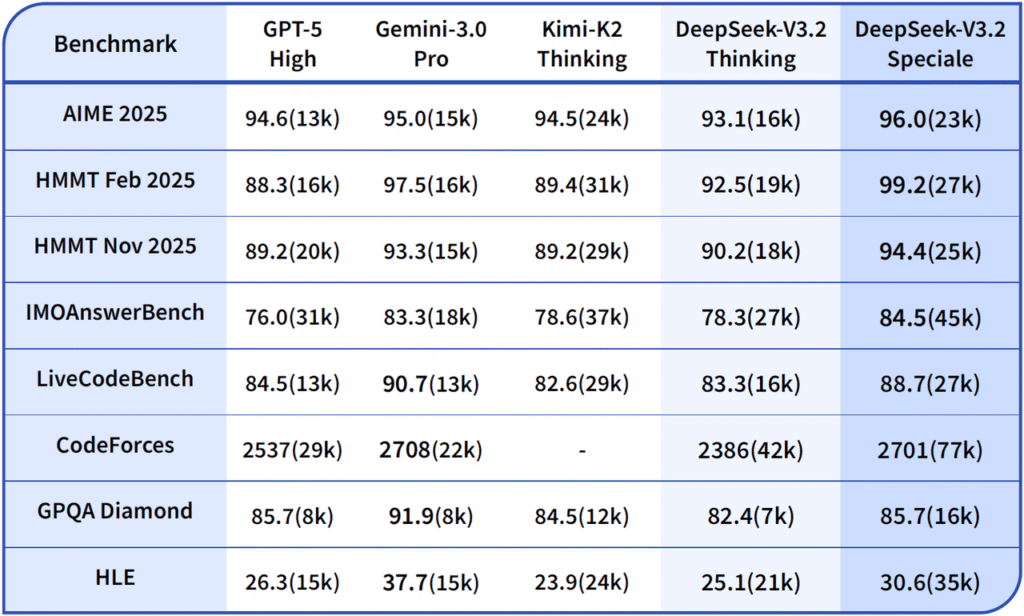
Deepseek 3.2 Benchmarks: Does It Really Rival GPT-5?
The short version: Yes, on many reasoning-heavy benchmarks it’s in the same league as GPT-5 and Gemini 3.0 Pro—sometimes ahead.
Math Competitions
Gold-medal level at IMO 2025 and IOI 2025:
- IMO 2025: 35/42 score (Speciale variant)
- IOI 2025: 492/600 score (Speciale variant)
These are the actual international Olympiad competitions, not simulated benchmarks. DeepSeek 3.2 Speciale achieved scores that would have earned gold medals.
Coding & Agent Tasks
Competitive with GPT-5-High on:
- SWE-Verified (real software bug fixing)
- Terminal-Bench 2.0 for complex coding workflows
Strong performance on:
- BrowseComp (web browsing and information extraction)
- SWE-bench style tasks (real-world software engineering)
The 3.2 line closely tracks or slightly improves on V3.1-Terminus while using fewer FLOPs per token.
Long-Context Understanding
DeepSeek 3.2 maintains strong performance across its full 128K context window, with particular strength in:
- Multi-document synthesis
- Long-form code analysis
- Extended dialogue coherence
Why DeepSeek Sparse Attention (DSA) Matters
Here’s the problem DSA solves:
Most transformer models still use dense self-attention: every token attends to every other token in the sequence.
That cost scales quadratically with context length. Going from 32K to 128K context becomes exponentially more expensive.
How DSA Works (Simple Explanation)
Think of it like this:
Dense attention = Reading an entire library to answer one question
Sparse attention = Skimming the table of contents, reading relevant chapters, and checking a few key references
DSA intelligently selects only around 2,048 key-value tokens per query token instead of tens of thousands.
Real-World Benefits
- Near-linear scaling in practice on long contexts
- Up to ~70% cost reduction for 128K-token inference compared to dense attention
- Almost no drop in benchmark performance versus the older V3.1 Terminus model
This is why Exp variant exists—to prove that you can maintain quality while slashing costs.
RL and Agentic Training: Why 3.2 Is So Good With Tools
DeepSeek didn’t just tweak the architecture. They also went hard on reinforcement learning and synthetic agent data.
The Training Approach
Post-training RL investment:
They dedicate over 10% of the pre-training compute budget purely to post-training RL—much more than many previous open models.
Custom agent environments:
- Built 1,800+ distinct environments
- Created ~85,000 complex prompts specifically for agentic tasks
- Focus areas: browsing, tools, multi-step workflows, error recovery
What This Means for You
The result: Deepseek 3.2 is unusually good at:
- Multi-step planning (“here’s a multi-day project, plan and execute it”)
- Calling tools and APIs in the right order
- Recovering from failures in longer workflows
- Context switching between different tasks within a conversation
Real-World Use Cases: What Users Are Saying
From Reddit & Community Forums
Developer feedback:
“Switched from GPT-4 to DeepSeek 3.2 Exp for our coding copilot. Cut our API costs by 60% with no noticeable quality drop.” — u/AIEngineer_2025
Research applications:
“Using Speciale for mathematical research. It’s genuinely helping with proof strategies in ways I didn’t expect from an AI.” — Academic researcher on X
Business automation:
“Running 3.2 Base for customer support automation. The long-context capability means it actually remembers entire support histories.” — SaaS founder
Enterprise Adoption
Several companies have reported successful deployments:
- Coding assistants replacing proprietary models
- Document analysis for legal and financial sectors
- Research summarization for academic institutions
- Multi-agent systems for complex workflow automation
Pricing, Availability, and Where to Run Deepseek 3.2
The other big question people are clearly Googling: “deepseek 3.2 pricing” and “is it really free?”
Open Weights & License
Weights are downloadable for all three variants on Hugging Face:
- Deepseek 3.2 Base
- Deepseek 3.2 Exp
- Deepseek 3.2 Speciale
License: Permissive MIT-style license
This allows:
- Commercial use
- Modification and fine-tuning
- Self-hosting
- Distribution
Only requirement: Retain the copyright notice
So yes, the model is “free” in the open-source sense.
The catch? Actually running a 685B-parameter MoE model requires serious hardware investment.
API Pricing
For hosted use:
DeepSeek’s official API:
- Cut costs by 50%+ with the 3.2 Exp release compared to their previous flagship
- Competitive per-million-token pricing
Third-party providers:
- Together AI
- OpenRouter
- Other inference providers
These expose deepseek 3.2 exp and related models with competitive pricing and long-context support.
The net effect:
Frontier-class reasoning at mid-tier prices, which is why investors keep calling DeepSeek a “price-war” catalyst in the AI space.
How to Start Using Deepseek 3.2 Today
Depending on your setup, here are your options:
Option 1: Just Want to Chat With It?
Easiest approach:
- Use DeepSeek’s own chat interface
- Try any OpenRouter-backed frontend that supports deepseek 3.2 exp or speciale
- No setup required, works in browser
Option 2: Building an App or Agent?
For developers:
- Use a provider like Together / OpenRouter for API access (no infra headaches)
- Start with Deepseek 3.2 or 3.2 Exp as your default model
- Selectively route “hard” tasks to 3.2 Speciale
Sample integration:
# Route based on complexity
if task_requires_deep_reasoning:
model = "deepseek-3.2-speciale"
else:
model = "deepseek-3.2-exp" # Cheaper for standard tasks
Option 3: Self-Hosting / Research / Finetuning?
For advanced users:
- Grab the model from Hugging Face:
deepseek-ai/DeepSeek-V3.2DeepSeek-V3.2-Exp-BaseDeepSeek-V3.2-Speciale
- Hardware requirements:
- Expect to need serious GPU memory for full-precision
- Ongoing research shows aggressive quantization can bring it down to ~100GB range with modest quality loss
- Community resources:
- Active Discord and GitHub communities
- Quantization guides and optimization tips
- Fine-tuning notebooks and examples
Why Deepseek 3.2 Matters for the AI Industry
Deepseek 3.2 isn’t just “yet another big model.” It represents three major shifts:
1. Open Weights Can Compete at the Frontier
For the first time, an open-source model genuinely competes with GPT-5 and Gemini 3.0 Pro on real, hard benchmarks—not just cherry-picked leaderboards.
This proves that the frontier isn’t exclusive to companies with billion-dollar budgets.
2. Efficiency Innovations Matter As Much As Scale
DeepSeek Sparse Attention shows that clever architecture choices can slash costs by 50-70% while maintaining quality.
This makes long-context, agentic workloads economically viable for everyone—not just tech giants.
3. True Open Science Accelerates Progress
The combination of:
- MIT licensing
- Transparent technical reports
- Detailed training methodologies
…means the “secret sauce” is truly shared, letting the entire ecosystem learn from and build on it.
The Bigger Picture
If you’re working with AI in 2025—whether as a researcher, indie hacker, or enterprise architect—deepseek 3.2 should be on your shortlist of default models.
And judging by those Google suggestions, the rest of the world is already trying to figure it out too.
Frequently Asked Questions
Q: Is DeepSeek 3.2 really as good as GPT-5?
On many reasoning and coding benchmarks, yes. It achieved gold-medal scores at IMO and IOI 2025, rivaling GPT-5’s performance on complex tasks.
Q: Which variant should I use?
- Daily work? Use Base or Exp
- Need maximum efficiency? Use Exp
- Research-grade reasoning? Use Speciale
Q: Can I use it commercially?
Yes, it’s MIT-licensed. You can modify, host, and use it commercially with minimal restrictions.
Q: How much does it cost?
The weights are free. API access pricing varies by provider but is generally 50%+ cheaper than comparable proprietary models.
Continue Your DeepSeek Journey: Related Guides
Ready to explore more about DeepSeek’s capabilities? Check out these in-depth guides:
DeepSeek OCR: Vision Language Model for Document Analysis
Learn how DeepSeek handles visual understanding and optical character recognition. This guide covers:
- Multi-modal document processing capabilities
- Real-world OCR accuracy and performance benchmarks
- Integration workflows for document extraction tasks
Best for: Developers building document analysis or visual AI applications.
DeepSeek Model V3: Complete Implementation Guide
Your technical handbook for working with DeepSeek V3, the predecessor to 3.2. Explore:
- Architecture deep-dive and model specifications
- Step-by-step setup and deployment instructions
- Fine-tuning strategies and optimization tips
Best for: Engineers who want hands-on implementation details and best practices.
Understanding DeepSeek R1: The Reasoning Revolution
Dive into DeepSeek’s approach to advanced reasoning and how R1 changed the game. Discover:
- The evolution of reasoning capabilities in DeepSeek models
- How reinforcement learning shapes model behavior
- Practical applications of enhanced reasoning
Best for: AI researchers and practitioners interested in the theoretical foundations behind DeepSeek’s success.
Ready to try DeepSeek 3.2? Start with the Exp variant for the best balance of cost and performance, or jump straight to Speciale if you’re tackling complex reasoning tasks.
Have questions or experiences with DeepSeek 3.2? Share them in the comments below.
Comments